
개인정보보호, 소프트웨어 정책


빅 데이터 분석 시장은 급속하게 변화되며, 가장 성장 잠재력이 있는 기술들은 포레스터 리서치 (Forrester Research)의 보고서에 따르면 빅 데이터를 이용하는 고객이 원하는 것을 실시간 예측 및 통합에 대한 기술들이 상위에 보이고 있다.
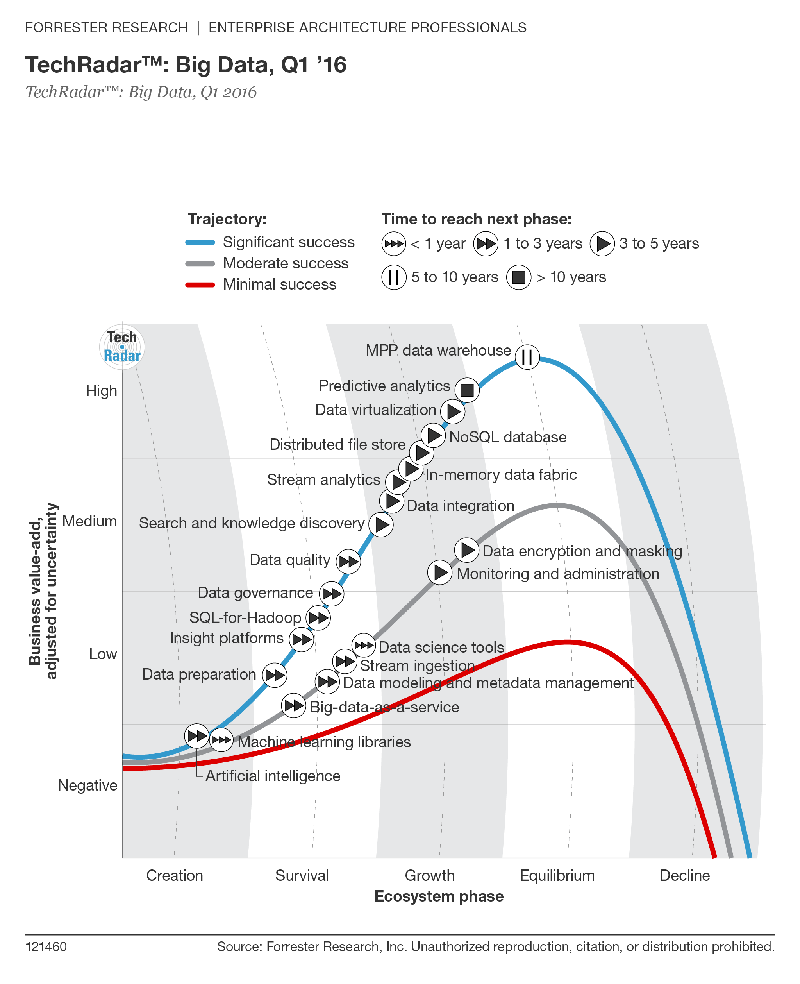 포레스터의 분석을 바탕으로 10 가장 인기있는 빅 데이터 기술은 다음과 같습니다
포레스터의 분석을 바탕으로 10 가장 인기있는 빅 데이터 기술은 다음과 같습니다
- Predictive 분석 : 기업은 발견 할 수 있도록 평가, 최적화 및 비즈니스 성과를 향상 시키거나 위험을 완화하기 위해 빅 데이터 소스를 분석하여 예측 모델을 배포하는 소프트웨어 및 / 또는 하드웨어 솔루션을 제공합니다.
- NoSQL 데이터베이스 : 키 – 값, 문서, 그래프 데이터베이스.
- Search과 지식 발견 : 도구와 기술 정보 및 파일 시스템, 데이터베이스, 스트림, API 및 다른 플랫폼 및 응용 프로그램과 같은 여러 소스에있는 비 구조화 및 구조화 된 대량의 데이터 저장소에서 새로운 통찰력의 셀프 서비스 추출을 지원하는.
- Stream 분석 : 필터링 골재 풍부하고, 서로 다른 여러 라이브 데이터 소스로부터 임의의 데이터 포맷으로의 데이터 처리량을 분석하는 소프트웨어.
- In-memory 데이터 구조 : 동적 랜덤 액세스 메모리를 가로 질러 (DRAM)의 데이터를 전송함으로써 대용량 데이터의 낮은 지연 액세스 해 처리를 제공하고 분산 컴퓨터 시스템의 플래시 또는 SSD.
- 분산 파일 저장 : 데이터 중복성 및 성능을 위해 자주 복제 된 방법으로 여러 노드에 저장되어있는 컴퓨터 네트워크.
- Data 가상화 : 실시간과 거의 실시간으로 같은 하둡과 같은 빅 데이터 소스와 분산 데이터 저장 등의 다양한 데이터 소스에서 정보를 제공하는 기술입니다.
- 데이터 통합 : 아마존 엘라스틱 맵리 듀스 (EMR), 아파치 하이브, 아파치 돼지, 아파치 스파크, 맵리 듀스, 카우치베이스 주식회사, 하둡 및 MongoDB를 같은 솔루션에서 데이터 오케스트레이션을위한 도구.
- Data 준비 : 성형 클렌징, 그리고 다양하고 지저분한 데이터를 공유, 소싱의 부담을 덜어 소프트웨어는 분석 데이터의 유용성을 가속화하기 위해 설정합니다.
- Data 품질 : 분산 데이터 저장 및 데이터베이스에 병렬 연산을 사용하여, 대형 고속 데이터 세트에 데이터 정제 및 농축을 수행 제품.