
개인정보보호, 소프트웨어 정책


빅데이터 시대 정보주체의 권리를 보호할 수 있는 데이터 연계·결합의 원칙 및 현재 국내외에서 이루어지고 있는 데이터 연계·결합의 현황 분석을 통하여 개선사항의 도출을 위하여 개인정보보호위원회가 발주한 과제의 결과물 입니다.
이 연구는 주요국가의 데이터 연계ㆍ결합 시 대상, 허용범위, 원칙, 안전조치 등에관한 법규정 및 운영사례를 조사 분석하고, 정보주체의 권리가 침해되지 않는 데이터 연계의 원칙, 기준 마련 및 관련 법제도 개선사항을 모색하였습니다. 이를 통해 국내의 ‘데이터 연계ㆍ결합을 위한 제도’ 도입방안 및 법제 정비방안을 도출하고자 하였습니다.
※ <전체 연구보고서> 파일은 온-나라 정책연구시스템에서 다운받으시거나 붙임자료를 참고하시기 바랍니다.
붙임자료
데이터 연계 결합 지원제도 도입방안 연구 – 개인정보보호위원회 2017년7월
1. 연구 필요성 및 목적
세계 주요 국가들은 공공의 이익을 위한 학술 연구를 활성화하고, 증거에 기반을 둔 정책 수립을 지원하기 위해 데이터 연계를 허용하면서도 정보주체의 개인정보를 보호하고 신뢰할 수 있는 데이터 이용 기반을 만들기 위한 법적·제도적 노력을 하고 있다. 데이터 연계를 통해서 데이터의 질을 향상시키거나, 하나의 데이터 소스로는 알 수 없는 새로운 정보를 생성해낼 수 있는데, 이를 통해 정책 결정 및 연구의 질을 높일 수 있다. 반면, 이와 같은 기법은 개인정보 주체의 개인정보 자기결정권 침해나 사생활의 비밀 침해 등의 문제를 야기할 수 있다.
주요 국가들의 전문적 중계기관들은 안전한 환경에서 개인정보가 포함된 데이터가 결합·연계될 수 있도록 지원한다. 데이터 연계 이슈와 관련하여 국내에서는 개인정보의 비식별화 등 기술적 조치에 대해서 주로 초점을 맞추는 경향이 있다. 그러나 비식별화는 데이터 거버넌스의 한 가지 요소일 뿐이다. 예를 들어, 영국의 행정데이터연구네트워크(ADRN)가 제시하는 5가지 안전 원칙은 데이터 비식별화에 대한 데이터 안전(Safe data)의 개념뿐 아니라 연구 인력(Safe people), 연구 프로젝트(Safe project), 연구 환경(Safe environment/settings), 연구 결과물(Safe results/output)을 포괄하는 보다 폭넓은 개념이다.
주요 국가들은 공익에 기여하면서도 안전한 데이터 거버넌스를 위해서 기술적인 조치뿐 아니라 데이터의 이용과 보호에 관련된 법제, 데이터 접근·연계 정책, 연구기관 혹은 데이터 연계기관의 인증, 심사절차, 데이터 접근 절차 등에 이르는 전반적인 보호 체제를 갖추고 있다.
이 모든 과정이 체계적으로 조율되지 못한다면, 자칫 데이터 연계 및 제공 과정에서 개인정보 침해가 발생하거나, 반대로 공익에 기여할 수 있는 데이터의 활용을 제약할 수 있을 것이다. 따라서 데이터 연계·결합을 활성화하기 위해서는 데이터의 수집·연계·제공에 이르는 전 과정에서 데이터의 활용 및 보호를 위한 데이터 거버넌스 체계가 수립될 필요가 있다.
본 연구는 데이터 연계·결합과 관련된 해외 주요 국가의 데이터 거버넌스 체제를 검토하여 우리 사회에 의미가 있는 시사점을 도출하고자 한다. 또한, 보건의료 및 통계 분야, 그리고 비식별 조치 전문기관을 통한 데이터 연계·결합 현황에 대한 분석을 통해 그 한계 및 문제점을 파악하고 데이터 연계·결합을 위한 제도 도입방안을 제시하고자 한다.
2. 연구의 범위
먼저 데이터 연계의 기본적인 개념과 유형 및 그 필요성 및 위험성을 살펴본 후 데이터 거버넌스의 원칙과 모델을 제시한다.
이어서 해외 주요 국가의 데이터 연계·결합 현황에 대하여 각국 개인정보 보호 법제, 보건의료 분야, 연구 목적의 데이터 연계, 통계 목적의 데이터 연계로 구분하여 검토한 후 시사점을 도출한다.
다음으로 국내 데이터 연계·결합 현황을 살펴보면서 우선 개인정보보호법 등 데이터 연계·결합 관련 국내 법제 및 보건의료, 통계 분야의 현황을 분석한다. 개인정보 비식별 조치 전문기관 및 기타 정부 부처 데이터 연계·결합 현황도 살펴본 후 문제점과 개선 방향을 제시한다.
마지막으로 국내 데이터 연계·결합을 위한 제도 개선 방안을 제안한다.
3. 연구 내용 및 결과
(1) 데이터 연계와 데이터 거버넌스
1) 데이터 연계
‘데이터 연계(Data Linkage)’란 두 개 이상의 출처로부터 동일인이나 동일한 사건, 기관, 장소에 연관된 정보를 함께 가져오는 것을 의미한다. 식별자 등을 이용해 정보를 결합함으로써 단일 출처의 정보만으로는 알기 힘든 정보 요소 간의 관계가 밝혀질 가능성이 있다. 데이터 연계는 레코드 연계(record linkage), 데이터 매칭(data matching), 데이터 통합(data integration) 등으로도 불린다.
데이터 연계 방법은 데이터셋의 상태나 연구의 목적 등에 따라 정확 연계, 확률연계, 통계적 연계, 다층 연계 등으로 나뉜다. 연계 데이터는 유형별로 횡단면 조사 데이터, 코호트 연구와 종적 연구, 등록부 데이터, 기타 행정 데이터 등이 있다.
데이터 연계는 새롭거나 발전된 통계의 생산, 현재 일부 정보가 존재하는 측정값들에 대한 추가적인 정보의 생산, 단일 데이터 소스로부터 얻을 수 있는 것보다 더 많은 단위의 폭넓은 변수 활용, 기존 데이터 소스의 개선이나 검증 가능성, 응답자 부담 감소 등의 측면에서 연구에 이익이 된다.
그러나 데이터 연계는 개인 식별에 관련된 데이터가 더욱 많아지기 때문에, 유출이나 공개 시의 위험성이 더욱 증가하게 된다. 이러한 위험을 낮추기 위해 각국은 연구 데이터셋에 대한 관리는 물론, 연계 프로세스를 단계별로 분리 구축하는 데이터 거버넌스 체계를 채택해 왔다.
2) 데이터의 활용과 보호를 위한 체계
데이터 연계가 수행되기 위해서는 데이터 보유기관으로부터 데이터 접근을 위한 승인을 받는 것에서부터 연구자 등 실제 데이터 이용자에게 개인정보 침해 위험을 최소화하는 방식으로 데이터를 제공하는 일련의 과정이 정비되어 있어야 한다. 데이터(정보)의 활용과 보호 전 과정에 걸쳐 적용되는 원칙, 법제도, 가이드라인 등의 체계를 ‘데이터 거버넌스’라고 부른다.
국제적으로 제안된 데이터 거버넌스 원칙으로는 OECD와 UN의 경우를 살펴볼 수 있다.
OECD는 환자의 프라이버시를 보호하면서 통계 혹은 연구 목적으로 보건의료 데이터를 이용하기 위해 입법 체계를 비롯한 ‘보건의료 데이터 거버넌스’를 제안해 왔다. 특히 OECD는 2017년 보건의료 데이터 거버넌스에 대한 이사회 권고를 발표하면서 ① 이해당사자의 관여와 참여, ② 기관 간 협업, ③ 공공부문 보건의료 정보시스템에 대한 보호조치, ④ 개인에 대한 명확한 정보 제공, ⑤ 설명에 기반을 둔 동의 체계 보장, ⑥ 보건의료 데이터를 연구 및 공익적 목적으로 사용하는 데 대한 검토와 승인 절차, ⑦ 공공 정보 체계를 통한 투명성 보장, ⑧ 프라이버시 보호, 정보 보안, 개인정보 이용에 대한 개인의 통제권을 보장하면서 정보 가용성을 증진하는 기술적 수단, ⑨ 감독과 평가 체계, ⑩ 적절한 교육훈련 및 기능 개발, ⑪ 통제권과 보호조치, ⑫ 개인 건강정보를 처리하는 기관들에 대한 인증 또는 인가 체계를 갖출 것을 권고하였다.
UN은 2014년 1월 총회에서 ‘UN 공식통계 기본 원칙’을 승인하며 통계 기관이 통계 편집을 위해 수집한 개별 데이터는, 엄격한 기밀성이 보장되고 통계 목적으로만 사용되어야 한다는 원칙 등을 밝혔다.
이러한 원칙에 조응하며 구축된 데이터 거버넌스 모델로는 우선 영국 행정데이터연구센터(ADRC)의 경우를 들 수 있다. ADRC는 그 설립 과정에서 ① 영국 4개 권역별 ADRC 설립, ② 연구 목적 행정 데이터 접근과 연계를 규정한 입법, ③ 국가적, 국제적인 모범 관행에 기반한, 전국적 연구 승인 절차, ④ 일반 대중의 참여 촉진, ⑤ 연구 목적 접근과 연계를 위한 재정 지원 등의 원칙을 수립해 왔다.
Rosalyn이 제안한 ‘DASSL 모델’은 개인정보 보호와 데이터 이용을 통한 공익의 균형을 달성하기 위해, ① 거버넌스, ② 연구 데이터 허브, ③ 제3자 데이터 연계 서비스, ④ 안전시설, ⑤ 연구 지원단, ⑥ 결과물 점검 및 공개 통제, ⑦ 대중 참여 및 소통을 데이터 거버넌스 모델의 주요 요소로 제안하였다.
특히 데이터 연계와 관련한 원칙 및 모델로는 유엔의 2009년 ‘통계 및 관련 연구 목적을 위해 수행되는 데이터 통합의 기밀성 관련 원칙과 가이드라인’을 살펴볼 필요가 있다. 여기서는 제안된 데이터 연계의 원칙과 관련 가이드라인은 다음과 같다. ① 데이터 통합은 통계 및 관련 연구 목적으로만 국가통계기구 및 국가통계시스템 내의 다른 기구에 의해서 수행되어야 한다. ② 국가통계기구는 자신의 국가통계 임무에 부합하고, 표준 승인 절차를 완료한 이후에만 데이터 통합을 수행해야 한다. ③ 데이터 통합 프로젝트의 공익은 데이터 이용과 관련한 프라이버시 혹은 기밀성 우려와 공식통계 시스템의 완전성에 미치는 위험보다 충분히 더 커야 한다. ④ 응답자에게 하지 않겠다고 특정하게 약속을 한 경우에 데이터는 통합되어서는 안 된다. ⑤ 통합 데이터는 승인된 통계 혹은 연구 목적으로만 이용되어야 하며, 애초에 승인된 목적에서 크게 벗어나는 경우 새로운 표준 승인 절차를 밟아야 한다. ⑥ 연계 데이터셋에 포함되는 단위 레코드 및 데이터 변수의 수가 승인된 목적을 위해 필요한 이상이어서는 안 된다. ⑦ 국가통계기구는 데이터 통합을 개방적이고 투명한 방식으로 수행해야 한다. ⑧ 데이터 통합으로부터 나온 통합 단위 레코드 데이터에 대한 접근은 일반적으로 국가통계기구의 허가된 직원으로 제한된다. 다른 통계적 마이크로데이터에 대한 외부인의 접근은, 명확한 법적 근거에 의해 허가되어야 하고 공식통계를 위한 데이터 사용 목적에 부합해야 한다.
한편 영국 행정데이터작업반은 4가지의 데이터 연계 모델을 제안하였다. 그 가운데 ‘신뢰할 수 있는 제3자 색인(trusted third party indexing, TTP)’ 모델의 경우, 절차 중에 어떤 참가자도 전체 데이터셋의 내용이나 식별 데이터를 다룰 수 없다는 점이 장점으로 꼽힌다.
(2) 해외 주요 국가의 데이터 연계·결합 현황
데이터 연계·결합이 기존에 다른 목적으로 수집된 데이터의 2차적 사용에 해당하는 경우가 많고, 서로 다른 목적으로 수집된 대규모 데이터베이스의 연계·결합 시 정보주체의 동의를 다시 획득하기가 쉽지 않다는 점에서, 데이터 연계·결합에 대한 법적 근거가 반드시 필요하다. 개인정보의 수집 목적 외 처리·제공은 개인정보보호원칙에 벗어난 예외적인 경우로서, 정보주체의 권리에 부정적인 영향을 미칠 수 있기 때문이다.
유럽연합, 영국, 독일, 미국 등 주요 국가 법률에서는 주로 공익을 위한 연구 및 통계 목적으로 데이터 연계·결합을 규정하고 있다.
1) 데이터 연계·결합 관련 해외 법제
가. 유럽연합
유럽연합의 개인정보보호 관련 법제는 ‘개인정보의 처리와 관련한 개인의 보호와 개인정보의 자유로운 이동에 관한 유럽의회 및 이사회의 지침 95/46/EC’ 등을 거쳐 2018년 ‘일반정보보호규정(GDPR)’ 발효를 앞두고 있다.
GDPR은 원칙적으로 개인정보를 연계·결합 등 처리할 때, 정보주체가 특정 목적에 대해 본인의 개인정보 처리를 동의하였거나 정보처리자의 법적 의무를 준수하는데 개인정보 처리가 필요한 경우, 공익상 이유 또는 정보처리자의 공식권한을 행사하기 위한 업무 수행에 개인정보 처리가 필요한 경우 등 제6조에 따라 적법하게 이루어져야 한다고 규정하고 있다.
다만 GDPR 제5조는 공익적인 기록 보존, 과학 및 역사 연구 또는 통계 목적의 개인정보 연계·결합은 원래의 수집 목적과 양립되는 것으로 인정하고 있다. 이 경우 제89조 (1)항에 따라 정보주체의 권리와 자유를 위해 암호화, 가명처리 등 적절한 안전조치를 취할 필요가 있다. 가명처리 정보는 추가 정보를 이용하여 개인을 식별할 수 있는 정보로서 식별할 수 있는 개인정보로 간주된다. 더 이상 개인정보가 아닌 익명 정보에는 개인정보보호원칙이 적용되지 않는다. 공익적인 기록 보존, 과학 및 역사 연구 또는 통계 목적을 위해 필요한 경우에 민감정보를 처리하려면 각국 법률에 근거를 두어야 하는데, 이 법률은 추구하는 목적에 비례하고 개인정보보호권의 본질을 존중하며 정보주체의 기본권 및 이익을 보호하기 위해 적절하고 구체적인 조치를 제공해야 한다.
특히 통계 목적의 개인정보 처리와 관련하여 GDPR은 유럽연합과 회원국 통계청이 공식적 통계를 작성하기 위해 수집하는 기밀 정보가 유럽연합 및 회원국 법률로써 보호되어야 한다고 언급하고 있다. 2009년 3월 제정된 ‘유럽의회 및 각료이사회 규정(EC) No 223/2009 (EU통계규정)’은 통계적 기밀성에 관한 제5장에서 개인정보를 보호하고 있다.
나. 영국
영국의 경우 보건의료서비스에서 2차적 목적으로 기밀 정보(개인 식별이 가능한 정보)를 합법적으로 처리하기 위해서는 해당 조직이 ① 정보주체(환자)로부터 설명에 기반을 둔 동의(informed consent)를 획득하거나 ② 동의를 받지 않아도 되는 법률적 기반이 있어야 한다. 법률적 예외는 일반적으로 ‘국가보건서비스법(NHS Act 2006)’의 Section 251을 통해서 이루어진다. section 251에 의해 기밀 정보(식별 가능한 환자 정보)에 접근할 수 있으려면, ① 정보 취득자의 목적이 환자 진료의 증진과 관련되어야 하며, ② 공익을 위한 것이어야 하며, ③ 모든 환자로부터 동의를 얻는 것이 불가능하거나 혹은 너무 비용이 많이 들거나, 기술적으로 어려운 경우에만 허용된다. 이 신청은 기밀성 자문 그룹(CAG)에 의해 검토된다. 설명에 기반을 둔 환자들의 동의도 얻지 않았고, section 251에 따른 승인도 얻지 못한 경우, 2차적 데이터의 전송은 익명화되어야 한다.
한편 2017년 봄 입법화된 영국의 ‘디지털 경제법(Digital Economy Act 2017)’은 제5부 제5장에서 ‘연구 목적의 공유’를 규정하고 공공기관이 보유한 정보를 연구 목적으로 다른 사람에게 제공될 수 있도록 하였다. 그 정보가 개인정보일 경우, 다음과 같은 조건을 만족해야 한다. ① 그 정보가 특정인을 식별하는 경우, 공개되기 전에 특정인의 신원이 해당 정보 내에서 식별되지 않도록, 그리고 (그 자체로 혹은 다른 정보와 결합하여) 그 정보로부터 특정인의 신원을 추론하는 것이 합리적으로 가능하지 않도록 처리되어야 한다. ② 공개를 위한 그 정보의 처리에 관여하는 모든 사람은 특정인을 식별할 수 있는 우발적인 정보의 공개 위험성을 최소화하고, 그러한 정보의 의도적인 공개를 방지하기 위한 합리적인 조처를 해야 한다. ③ 이 공개는 공공기관에 의해, 혹은 공공기관이 아닌 경우 정보공개를 위한 처리에 관여한 사람에 의해 이루어져야 한다. ④ 정보가 공개되는 연구는 사전 승인을 받아야 한다. ⑤ 공개를 위한 정보의 처리에 관여한 공공기관 및 사람, 정보를 제공받은 사람, 연구 목적으로 그 정보를 이용하는 사람은 사전 승인을 받아야 한다. ⑥ 정보를 공개하거나 그 처리에 관여한 사람은 70조의 실행규약을 유념해야 한다.
다. 독일
독일 보건의료서비스는 ‘독일사회법전(SGB)’에 의해 규율되고, SGB X은 건강보험 관련 데이터를 포함한 사회 데이터의 보호를 규율하고 있다. 사회 데이터의 전송은 일정한 경우에 허용될 수 있는데, ① 사회서비스 학술 연구 혹은 노동 시장 및 직업에 관한 학술 연구 프로젝트를 위해 필요할 경우, 혹은 ② 공공기관이 자신의 업무와 관련하여 사회서비스 분야의 계획을 위한 프로젝트에 필요한 경우이다. 이때 정보주체의 정당한 이익이 영향을 받지 않아야 하고, 연구 혹은 계획의 공익성이 정보주체의 이익보다 훨씬 커야 한다. 합리적으로 개인의 동의를 얻을 수 있을 때는 해당 개인의 동의 없는 전송이 허용되지 않는다. 위 프로젝트의 개시에 반드시 필요한 정보주체의 성과 이름, 주소, 전화번호, 구조적 특징 또한 설문조사를 위해 전송될 수 있다. 이러한 전송은 최고 연방기관 혹은 해당 데이터가 유래한 지역을 책임지는 주 기관의 사전 승인을 얻어야 한다.
독일 각 주는 2009 ‘연방암등록데이터법’에 따라 암등록데이터센터(ZfKD)에 암등록 데이터를 제공한다. ZfKD는 신청에 따라 제3자에게 데이터 이용을 허락할 수 있는데 이 경우 정당성, 특히 학술적 이익이 입증되어야 한다. 이용의 범위나 공개는 계약에 의해 규율된다. ZfKD는 일정 기간 후에 통제번호를 삭제하기 때문에, 원 데이터에 오류가 있을 경우에 이를 나중에 식별하거나 수정하는 것이 불가능하다. 실제 개별 데이터로 연결하여 확인할 수 없기 때문이다.
한편, 독일 연방통계의 작성과 관련된 원칙, 조직, 활동을 규율하는 ‘연방통계법(Bundesstatistikgesetz)’은 13a조에서 통계 목적의 데이터 연계에 관한 사항을 규정하고 있다. 또 제16조(기밀성)에 따라 연방통계 목적으로 제공된 개인에 관한 데이터는 특정한 법률에 명시된 바에 의하지 않고는, 연방통계의 생산을 맡은 공무원 및 공공서비스 종사자에 의해 공개되어서는 안 된다. 다만 관련된 사람이 서면으로 동의한 경우, 공공기관과 관련되거나 연방통계 작성을 위한 법 조항에 근거하여 정보 제공 의무가 있는 경우, 연방통계청 혹은 주 통계청에 의해 다른 응답자의 개별 데이터와 결합되고 통계 결과값으로 제시된 경우, 응답자나 당사자와 관련이 없는 개별 데이터인 경우 등에는 기밀성 의무에서 예외를 인정받는다. 학술 프로젝트의 수행을 목적으로, 연방통계청 및 주 통계청은 고등교육기관 혹은 독립적 학술 연구를 수행하는 다른 기관에 개별 데이터를 제공할 수 있는데, 이 개별 데이터를 통해 응답자 등 개인을 식별하기 위해 비합리적 시간, 비용, 인력이 소요되는 경우, 즉 사실상 익명화된 개별 데이터인 경우에 한한다. 또한, 연방통계청 및 주 통계청의 특별보호구역 내에서, 기밀성을 보호하기 위한 효과적인 조치가 취해진 경우, 공식적으로 익명화된 개별 데이터에 대한 접근을 제공할 수 있다. 공무원, 공공서비스를 위해 특별선서를 한 사람, 혹은 7항에 따라 기밀성 서약을 한 사람에게만 개별 데이터에 대한 접근 권한이 주어진다. 개별 데이터는 오로지 전송된 목적으로만 사용되어야 한다. 특히 학술 연구 목적으로 전송된 개별 데이터의 경우, 학술 프로젝트가 완료되는 즉시 삭제되어야 한다.
라. 프랑스
프랑스의 경우 ‘정보, 파일 및 자유에 관한 법률’에 따라, 공공서비스를 관리하는 하나 이상의 법인에 속하고, 서로 다른 공익 목적의 파일들의 연계, 혹은 주목적이 서로 다른 기관에 속하는 파일의 연계 목적으로 자동화된 처리를 하는 경우, 프랑스의 개인정보 감독기구인 CNIL의 허가를 받는다. 또한, 국가등록번호인 사회보장번호(NIR)를 포함한 데이터의 처리도 CNIL의 허가를 받아야 한다. 이때의 정보처리는 오로지 과학 및 역사 연구만을 목적으로 하는 경우에 해당하며, 국가등록번호가 각 연구 프로젝트에 고유한 특정한 임의의 코드로 교체되는 방식으로 사전에 암호화 처리되어야 한다. 암호화 작업 및 그로부터 나온 코드를 통한 파일의 연계는 동일한 처리자가 수행해서는 안 된다. 암호화 작업은 CNIL의 공개된 의견을 받은 후에 국참사원의 시행령으로 규정한 주기로 갱신되어야 한다.
또한, 이 법은 제9장에서 보건의료 분야의 조사, 연구, 평가 목적의 개인정보 처리에 대해 상세하게 규정하고 있다. 보건 분야의 공익적인 연구, 조사 혹은 평가를 목적으로 한 개인정보의 처리는 CNIL의 허가를 받아야 하는데, CNIL은 ‘공공보건법’ L1121-1조에 규정된 인간연구 관련 허가 요청을 위한 자문위원회, 혹은 인간연구 외의 연구 및 평가 신청 승인을 위한 자문위원회의 의견을 받아 결정을 내린다. 신청자가 처리가 예상되는 개인정보 중에 특정 정보의 필요성을 입증할 충분한 증거를 제시하지 못한다면, CNIL은 해당 정보를 보유한 기관에 그 정보의 제공을 금지하고 단지 일부 제한된 데이터의 처리만 허용하도록 할 수 있다.
프랑스 통계법인 ‘통계 분야의 법적 의무, 조정 및 기밀성에 관한 법률’ 제6조는 통계 정보의 기밀성 보호를 다루고 있으며, 사적 성격의 사실과 행동에 관련된 설문조사의 개별 데이터는 원칙적으로 설문이 수행된 후 75년, 혹은 당사자 사망 이후 25년 동안 공개되지 않도록 규정하고 있다. 다만, 공식통계 혹은 학술적·역사적 연구 목적을 위해, 통계 기밀성 위원회의 의견을 청취한 후, 아카이브 행정당국의 결정에 따라 이루어질 경우에는 예외이다.
개인건강정보의 전송 절차는 절대 개인 식별을 허용해서는 안 된다. 다만 ‘정보, 파일 및 자유에 관한 법률’에 따라, 통계상 직간접적 식별요소가 필요할 경우, 특히 서로 다른 개인 소스의 데이터 결합 목적을 위해서만 예외가 허용된다. 이 목적을 위해 데이터 처리 허가를 받은 법인의 지정 책임자만이 통계청에 해당하는 INSEE 혹은 공공보건정책에 참여하는 부처의 통계부서에 전송된 개인건강정보를 전송받을 수 있다. 데이터 사용 후에는 개인식별요소가 폐기되어야 한다.
마. 미국
미국에는 공공과 민간을 모두 포괄하는 개인정보 보호법제가 없다. 연방정부가 보유한 개인정보를 규율하는 ‘프라이버시법’은 연방기관의 기록 시스템에서 유지되는 개인식별정보(Personally Identifiable Information)의 처리를 규율한다. 원칙적으로 어떠한 기관도 개인의 서면 요청 혹은 사전 서면 동의가 없으면 보유 개인정보를 다른 사람이나 기관에 공개해서는 안 된다. 다만, 12가지의 법정 예외를 두고 있는데, title 13 조항에 따른 인구조사, 설문조사, 관련 활동을 계획 혹은 수행하기 위한 목적으로 인구조사국에 제공하는 경우, 해당 기관에 사전에 해당 기록이 오로지 통계 조사 혹은 보고기록으로만 사용될 것임을 서면으로 확인받고 개인식별이 불가능한 형태로 전송할 경우가 이에 포함된다. 이 조항에 따라 공공기관의 기록은 통계 목적으로 인구조사국에 전송될 수 있다.
한편 보건의료 관련 법률인 ‘건강보험 양도 및 책임법(HIPAA)’은 ‘보호되는 건강정보(Protected Health Information, PHI)’로서 개인식별이 가능한 건강정보(individually identifiable health information)를 규정하고 있으며, 원칙적으로 이 법 적용을 받는 기관이 치료, 지불, 보건의료 운영 등의 촉진 목적으로만 환자의 서면 허가 없이 개인식별이 가능한 건강정보를 이용 및 공개할 수 있다. 다른 목적으로 이용할 경우에는 정보주체의 서면 동의가 있어야 한다. HIPAA 프라이버시 규칙은 연구 목적의 PHI의 이용 혹은 공개를 다음과 같은 조건 하에 허용한다. 원칙적으로 정보주체의 서면 허가 없이는 PHI를 이용 및 공개할 수 없지만, ① 기관평가위원회 혹은 프라이버시 위원회로부터 허가 예외의 승인을 받은 경우, 연구 준비 평가를 위한 경우, 사망자 정보에 관한 연구인 경우, ② 이름, 주소, 전화번호, 사회보장번호 등 18개 식별자를 제거하는 등 PHI가 비식별화된 경우, ③ 연구, 공중보건, 보건의료 운영의 목적으로 데이터 이용계약이 체결되고 특정한 직접 식별자가 제거된 ‘제한된 데이터셋’의 형태로 제공될 경우에는 서면 허가 없이 PHI를 연구 목적으로 이용 및 공개할 수 있다. HIPAA 법의 적용을 받는 기관은 제한적이기 때문에 건강보험업체, 보건의료 제공자, 공공기관 등에 소속되지 않은 연구자의 경우 프라이버시 보호를 위한 어떠한 법적 규율도 받지 않는다.
미국의 통계 관련 법률로서 ‘기밀정보의 보호 및 통계 효율성에 관한 법률’은 미국 통계 관련 기관들 사이에 통계 목적으로 수집되는 정보에 대해 단일한 기밀성 보호 기준을 수립하고, 노동통계국, 경제분석국, 인구조사국 등 지정통계기관 사이에 일부 데이터의 공유를 허용하고 있다. 기밀 정보의 보호를 다루는 이 법의 A절에서는, 통계 목적의 데이터 및 정보는 오로지 통계 목적으로만 이용할 것을 규정하고 있고, 이 정보들은 응답자의 동의가 있을 경우를 제외하고는 통계 목적 외 사용을 위해 개인 식별이 가능한 형태로 제공되지 않으며, 이러한 공개는 해당 기관이 승인했을 경우에만 가능함을 규정하고 있다. ‘인구조사법’은 미 상무부 장관이 이 법에 따른 업무와 관련된 정보를 다른 부처, 기관 등에 요청할 수 있고, 필요한 기록, 보고 등의 자료 복사본을 주, 시 등 다른 정보 단위 혹은 민간의 개인이나 기관으로부터 획득할 수 있도록 하였다. 정보의 기밀성에 관한 제9조는 법에서 규정한 예외를 제외하고는 누구도 이 법에 따라 수집된 정보를 본래 통계 목적 외의 목적으로 사용해서는 안 되고, 특정한 개인 혹은 기관이 식별되는 방식으로 공개되어서는 안 된다는 점 등을 규정하고 있다.
바. 뉴질랜드
뉴질랜드는 통계청이 개인정보의 수집, 저장, 이용에 관해 ‘개인정보보호법 1993’에서 규정한 프라이버시 원칙을 준수하도록 하였다. 통계법은 응답자(개인정보제공자)에게만 적용되고, 개인정보보호법은 응답자, 통계청 직원, 연구자 등 통계청 서비스이용자 모두에게 적용된다. 예를 들어 개인정보 공개 제한 원칙에 따라 몇 가지 예외를 제외하고는 개인정보가 제3자에게 공개(제공)되지 않아야 한다. 통계청도 통계법에 따라 응답자의 동의 없이는 통계청 밖으로 응답자의 정보를 제공하지 않는다. 그러나 정부 통계관의 승인에 따라, 비식별화된 정보를 승인된 연구자에게, 승인된 연구 목적을 위해, 안전한 환경에서 제공할 수 있다. 또한, 고유식별자 보호 원칙에 따라 통계 및 연구 목적의 데이터에서 조세번호, 운전면허증 번호, 여권 번호 등 개인식별정보를 제거하며, 통계청의 임의의 고유식별자로 대체된다.
뉴질랜드 ‘통계법’ 제37조(정보 보안)는 통계청이 수집한 정보에 대하여 통계 목적으로만 사용되어야 하고, 개인에 대한 세부 정보 혹은 질의에 대한 응답에는 통계청 직원 외에 접근하거나 공개되지 않아야 하고, 통계청이 공개하는 모든 통계 정보는 (개인이 동의했거나, 합리적으로 예측할 수 없는 불가피한 경우가 아니면) 세부 정보가 식별될 수 있는 방식으로 공개되어서는 안 된다고 규정하였다. 제공자의 허락, 공동 설문조사, 연구 및 통계 목적의 공개, 역사적 문서의 경우에는 예외적으로 마이크로데이터에 대한 접근이 허용된다.
2) 보건의료 분야 데이터 연계 현황
가. 영국
영국은 국가보건서비스(NHS)를 통한 공공영역이 보건의료서비스를 담당하고 있기 때문에 OECD 국가 중 가장 광범한 국가적 보건의료 데이터셋을 보유하고 있다. 다만 데이터 수집 및 접근 체제가 잉글랜드, 웨일즈, 스코틀랜드, 북아일랜드 등 지역별로 분할되어 있다.
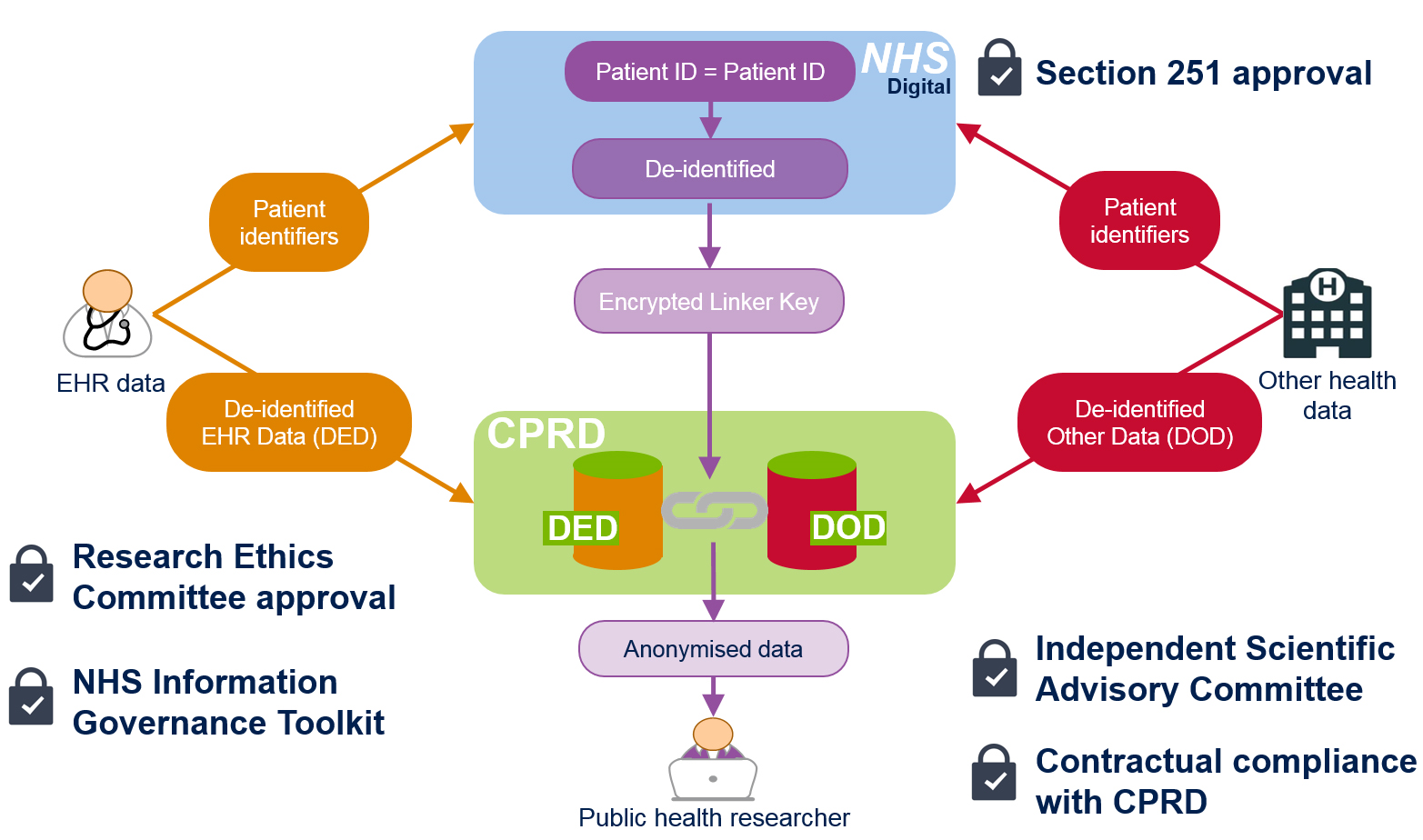
잉글랜드 지역 보건의료 분야 데이터 연계는 ‘임상시험연구데이터링크(CPRD)’가 대표적이다. CPRD는 비영리 연구지원을 목적으로 하는 복지부 산하 기관이며, 1987년부터 공공보건 연구를 위해 익명화된 1차 진료기록을 제공해왔다. CPRD는 NHS 번호, 이름, 전체 생년월일, 주소, 의사들의 진료메모 등은 수집하지 않는다. 일반의는 환자들의 비식별 데이터를 CPRD에 제공할지 여부를 선택할 수 있으며, 개인 환자가 원하지 않을 경우 CPRD에의 개인정보 제공을 거부할 수 있다(opt-out). 데이터 연계는 다음과 같은 절차에 의해서 이루어진다. ① 매년 CPRD는 공공보건연구 목적으로 익명화된 연계 데이터를 제공하는 것에 대해 보건연구당국의 Section 251 규제 승인을 받아야 한다. ② 데이터 연계는, 환자식별정보를 합법적으로 수집할 권한을 가진 잉글랜드의 법정 기구인 NHS Digital에 의해 이루어진다. 즉, NHS Digital 이 ‘신뢰할 수 있는 제3자(TTP)’의 역할을 수행한다. ③ 연계를 위해, 일반의가 수집한 환자식별정보(NHS 번호, 생년월일, 우편번호, 성별)와 다른 데이터셋의 식별정보가 NHS Digital로 보내진다. ④ NHS Digital은 두 데이터셋에서 환자식별정보를 매칭하여, 환자식별정보를 포함하지 않은 암호화된 연계키(encrypted linker key)를 산출한다. ⑤ NHS Digital은 CPRD가 비식별 데이터셋을 연계할 수 있도록 암호화된 연계키를 CPRD에 보낸다. ⑥ CPRD는 일반의나 NHS Digital로부터 절대 환자식별정보를 받지 않는다. ⑦ 공공보건연구 목적으로 연계 데이터에 접근하고자 하는 연구자는 독립적 과학자문위원회(ISAC)의 승인을 받아야 한다. ⑧ ISAC의 승인에 따라 연구자에게 익명화된 데이터셋을 제공하기 이전에 추가로 암호화한다. 라이선스를 가진 연구자가 ISAC이 승인한 연구를 수행하는 경우에는 CPRD가 보유한 익명화된 1차 진료 데이터베이스에 온라인으로 접근할 수 있다. CPRD 데이터 접근을 위한 라이선스 이용조건은, 데이터 접근이 공익적인 의료연구 목적으로 제한되고, 데이터셋은 승인된 연구로만 사용되어야 하며, 환자, 병원, 의사에 대한 식별 시도가 특히 금지된다는 점 등이 규정되어 있다.
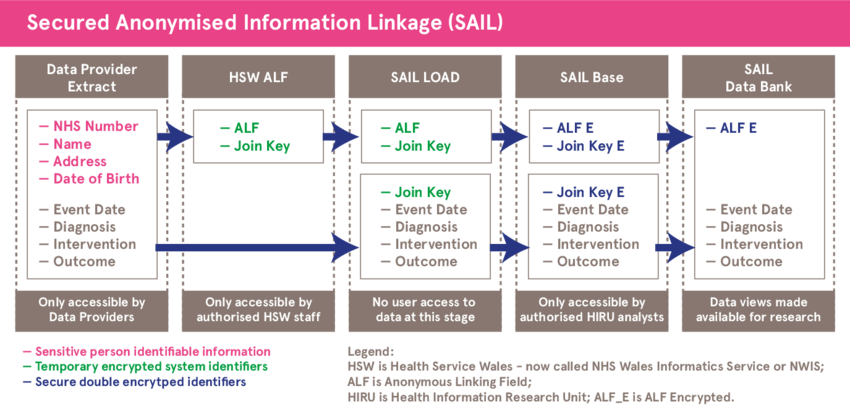
영국 웨일즈 SAIL DataBank의 경우에는 보건 관련 연구를 위해 익명화된 개인 기반 데이터의 저장 및 이용을 제공한다. SAIL Databank 는 CPRD의 경우와 마찬가지로 개인식별정보를 보유하고 있지 않으며 익명화된 데이터만 보유하고 있는데 연구자의 요청에 따라 데이터 연계를 제공한다. 다만 연계를 위하여 신뢰할 수 있는 제3자(TTP)의 역할을 하는 NHS 웨일즈 정보서비스(NWIS)가 연계를 위한 결합 키값인 익명연계필드(ALF)를 생성한 후 SAIL Databank에 제공한다. SAIL Databank는 ALF를 다시 암호화하여 서로 다른 익명 데이터셋을 연계하는데 사용한다. SAIL Databank 역시 공익에 기여할 수 있는 순수 연구목적으로만 데이터에 대한 접근을 허용하고 있다. 데이터에 접근하기 위해서는 독립적인 정보거버넌스검토패널의 승인을 받아야 한다. 연구 제안서가 승인되면, 모든 연구자는 데이터에 접근하기 전에 적절한 정보 거버넌스에 대한 훈련을 받아야 하며 훈련 자격증은 2년간 유효하다.
데이터 접근을 원하는 연구자들은 훈련을 마친 후 SAIL Gateway 사용 승인을 받는다. SAIL Gateway는 보안이 되는 안전한 환경에서 연구가 수행될 수 있도록 프라이버시 보호를 위한 안전시설이자 원격접근시스템으로 마련된 것이다. 연계 데이터를 바로 제공하기보다는 SAIL Gateway를 통해 접근하도록 하는 것은 혹시 있을 수 있는 연계 공격에 대비하기 위한 것이다. SAIL Gateway 사용이 승인된 연구자들은 SAIL 데이터 접근 계약을 체결하며 연구자가 요청한 특정 데이터는 ‘읽기전용’으로 접근할 수 있다. 연구가 완료되면 연구자들은 그 개인정보 침해 위험성에 대해 SAIL 데이터 관리자의 검토를 받은 후 자신의 연구결과물을 SAIL Gateway에서 가지고 나갈 수 있다.
한편, 2016년 7월 영국 보건의료 빅데이터 care.data 프로그램의 운영이 취소되었다. care.data는 기존에 병원 환자 정보를 보유하고 있던 HSCIC의 국가 데이터베이스에 일반의가 보유한 환자정보까지 집적하려는 NHS 잉글랜드의 사업으로 2013년 시작되었다. 일반의 시스템으로부터 추출하는 데이터는 이첩, NHS 처방전, 가족력, 예방접종, 혈액검사결과, 체질량 지수, 흡연/음주습관 등이다. care.data의 데이터는 직접적인 진료 목적이 아닌, 의료 서비스 계획이나 의학 연구 등 2차적 목적을 위해 활용될 예정이었다. NHS 내 기관뿐 아니라, NHS 외부의 제약회사, 보건 자선단체, 대학, 병원 위탁단체, 싱크탱크 및 다른 사기업 등에 제공될 수 있었다. 환자들은 일반의가 보유한 자기 정보를 HSCIC에 전송하는 것에 대해서, 혹은 HSCIC로 전송된 데이터를 제3자에게 전송하는 것에 대해서 거부권(opt-out)을 행사할 수 있다. 그럼에도 불구하고 care.data 사업은 많은 사회적 반발을 가져왔다.
논란이 일자 2015년 9월 영국 복지부는 ‘복지 질 위원회’에 NHS의 데이터 보안에 대한 검토를, 보건복지를 위한 국가데이터 가디언인 칼디콧에 데이터 보안 및 동의에 대한 독립적 검토를 요청했고, 보고서 권고에 따라 care.data 프로그램이 일단 취소되었다. care.data 사업의 실패는 개인정보의 수집·활용을 촉진하기 위한 사업에서 보안 및 개인정보보호에 대한 대중의 신뢰를 얻는 것이 얼마나 중요한지, 그리고 해당 사업을 추진하는 당국이 사업의 내용을 투명하게 공개하고 관련 이해당사자와 충분히 협의하는 것이 얼마나 중요한지를 보여준다.
나. 호주 PHRN
호주의 인구보건연구네트워크 PHRN은 보건 정보를 안전하게 관리할 수 있는 국가적인 데이터 연계 기반을 구축하기 위해 설립되었다. PHRN 연계 데이터에 접근할 수 있는 연구의 자격 요건은, 공중 보건의 증진·보호·유지에 기여할 것, 보건 서비스의 계획·평가·전달을 촉진할 것, 보건 데이터 수집·보건 관련 데이터 연계·보건 관련 통계의 편집 및 활용과 관련된 연구 방법 증진에 기여할 것 등이다. 연계 데이터를 사용하는 연구 프로젝트는 데이터 연계기구, 각 데이터셋을 보유한 데이터 보유기관들, 인간연구윤리위원회 등 세 기관의 승인을 얻어야 한다.
데이터 연계 절차로는 우선 연구자가 데이터 연계기구에 데이터 연계 프로젝트를 신청한다. 프로젝트가 승인되면 데이터 연계기구는 관련 데이터 보유기관에 데이터 연계를 위한 개인 식별자로서 연계 변수를 요청한다. 데이터 보유기관은 식별정보와 함께 레코드 ID나 환자 ID를 생성하여 데이터 연계기구에 보내는데, 프라이버시 보호를 위해 이 ID는 본래의 레코드 ID나 환자 ID가 아니라 프로젝트 고유의 ID가 권장된다. 데이터 연계기구는 연계 ID인 프로젝트 키를 생성하여 각 데이터 보유기관에 전달한다. 각 데이터 보유기관은 프로젝트 키가 결합된 콘텐츠 데이터 파일을 연구자에게 전달한다.
PHRN에서 개인정보 보호를 위한 중요한 원칙 중 하나가 ‘분리 원칙(separation principles)’이다. 그 의미는 다음과 같다. ① 연계 데이터와 콘텐츠 데이터의 분리. 연계를 위한 개인정보는 콘텐츠 데이터와 분리되어, 데이터 연계자에게는 연계 ID 생성을 위한 개인정보만 제공된다. ② 기능과 책임의 분리. 데이터 연계 절차와 데이터 보유 및 추출 기능을 분리한다. 데이터 연계를 수행하는 사람은 연구자와 분리되어 있어야 하며, 콘텐츠 데이터 연구에 참여할 수 없다. 정보의 이용, 제공, 보유 또한 제한된다. 연구자는 특정 프로젝트를 위한 정보에만 접근이 허용되며, 승인받은 방식으로 이용해야 한다. 프로젝트의 연구자들은 신원을 확인받고 승인되어야 하며, 다른 사람에게 정보를 주어서는 안 된다. 정보는 승인받은 기간 동안만 보관되며, 그 이후에는 데이터 보유자에게 반환하거나 삭제된다.
다. 미국
보건의료서비스를 민간 제공자와 보험사가 주도하고 있는 미국은 보건의료 데이터의 수집 및 보관도 다양하게 분산되어 있다. 연구 목적의 데이터 접근을 위한 계약 체결도 개별 업체를 매개로 해야 한다. 보통 사례별로 이용허락이 이루어지며, 연구 출판 전에 연구결과에 대한 사전 승인을 요구할 수 있다. 민간 영역의 데이터 연계는 통상 업체 내에서 이루어지며, 다른 업체와의 데이터 연계에 제한을 두고 있다. 일반적으로 비식별 데이터로부터 개인 식별을 시도하거나 다른 데이터 소스와 연계하는 것을 제한한다.
미국 국가보건통계센터(NCHS)는 자신이 보유한 데이터의 식별자를 제거한 후 공개사용 데이터 파일로 만들어 공개하고 있다. 미국의 ‘공공보건서비스법’ Section 308 (d) 등의 규정에 따라 공개사용 데이터 파일의 이용자는 다음 조건에서 이를 사용해야 한다. ① 데이터셋은 통계 보고 및 분석 목적으로만 사용해야 한다. ② 의도하지 않게 개인 및 기관의 신원이 노출될 경우 이를 사용하지 말고 NCHS 책임자에게 알려야 한다. ③ 이 데이터셋을 개인 식별이 가능한 다른 NCHS의 데이터나 외부 데이터와 연계해서는 안 된다. ④ 공개사용 데이터를 이용하는 것은 위의 법적 요구조건을 준수하겠다는 ‘데이터 이용자 계약’에 서명한 것이 된다. 또 NCHS는 연구자를 위해 이름, 사회보장번호, 주소 등 직접 식별자는 제거했지만, 지리정보 등 간접 식별자를 포함한 ‘제한된 데이터(restricted data)’에 대한 접근을 허용하기 위해 연구데이터센터(RDC)를 두고 있다. 연구데이터센터를 이용할 때는 연구 제안서 승인, 승인 범위 안에서 분석 및 연구, 결과물 공개에 대한 제한 등에 대해 연구데이터센터와 협의해야 한다. 개인 수준의 데이터는 센터의 시설로부터 가지고 나갈 수 없으며 전자기기를 사용할 수 없다.
3) 연구 목적 데이터 연계 현황
가. 영국 ADRN
영국의 행정데이터연구네트워크(ADRN)는 사회, 경제 연구자들에게 안전한 환경에서, 연계된 비식별 행정 데이터에 대한 접근을 제공하기 위한 네트워크이다. ADRN은 연구자들을 대신하여 요청할 데이터의 범위를 검토하고, 데이터 보유기관과 협의를 진행하며, 신뢰할 수 있는 제3자(TTP)를 통해 데이터를 연계하고, 연계된 비식별 데이터에 접근할 수 있는 보안 환경을 제공하는 기구로서, 행정 데이터를 직접 보유하고 있는 것은 아니다.
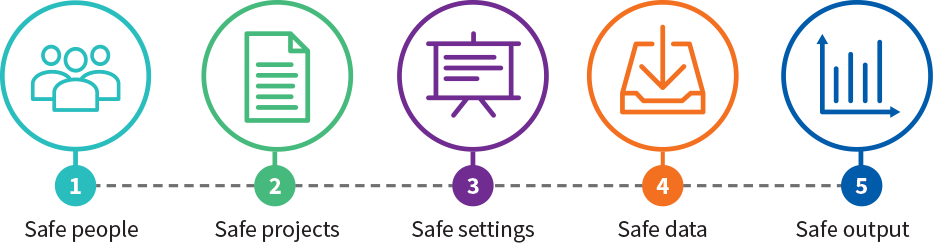
ADRN은 영국 데이터 서비스가 만든 ‘데이터 공유를 위한 5가지 안전 원칙’에 따라 운영된다. 이는 데이터 비식별화 및 TTP 데이터 연계 등 데이터 안전(Safe data)는 물론 인력 안전(Safe people), 연구 안전(Safe project), 환경 안전(Safe environment), 결과물 안전(Safe results) 등의 원칙이다.
ADRN의 데이터 연계는 다음 절차를 따라 이루어진다. ① 연구 제안서의 승인이 이루어지고 연구자가 훈련을 받은 후, ADRN은 프로젝트 관련 데이터의 제공을 위해 데이터 보유기관과 협상을 진행한다. ADRN에 신청하는 모든 연구 프로젝트는, 비영리적 연구 목적이어야 하고, 명확한 과학적 이익과 잠재적인 공익이 있음을 입증해야 하며, 연구 과제에 대한 답을 찾기 위해 부서 수준의 행정 데이터가 필요하다는 것을 보여주어야 한다. 승인 패널은 연구 프로젝트가 윤리적인지, 합법적인지, 실현 가능한지, 과학적 가치가 있는지, 사회에 이익이 되는지를 결정한다. 연구자의 자격요건은 학계, 공공영역, 공동체 혹은 자원봉사 영역, 연구기관 소속이어야 한다. 연구자는 안전한 연구 데이터 이용자 환경 훈련에 참여해야 하고 이용약관과 위반정책에 서명해야 한다. ② 데이터를 보유한 정부 부처는 각 레코드에 고유한 참조번호(reference number)를 부여한다. 그리고 이름, 생년월일 등 사람들을 직접 식별할 수 있는 식별자를 분리한다. ③ 데이터 보유기관들은 식별정보를 고유 참조번호로 대체한 데이터를 ADRC 에 보낸다. 직접 개인을 식별할 수 있는 정보는 데이터와 분리하여 각 레코드의 고유 참조번호와 함께 신뢰할 수 있는 제3자(TTP)에게 보낸다. ④ TTP는 고유 참조번호와 식별정보를 사용하여 이 정보들을 매칭한다. 그리고 개인 식별정보를 삭제한 후 매칭된 고유 참조번호만을 남긴다. ⑤ 색인키(index key)는 서로 다른 데이터 집합에서 어떤 참조번호가 같은 사람과 관련되는지를 보여준다. TTP는 색인키를 ADRC에 보낸다. ⑥ ADRC는 색인키를 사용하여 서로 다른 기관들이 보내온 데이터 집합을 연계한다. 그리고 색인키와 참조번호를 지운 후에 연구자에게 연계된 데이터에 대한 접근을 제공한다.
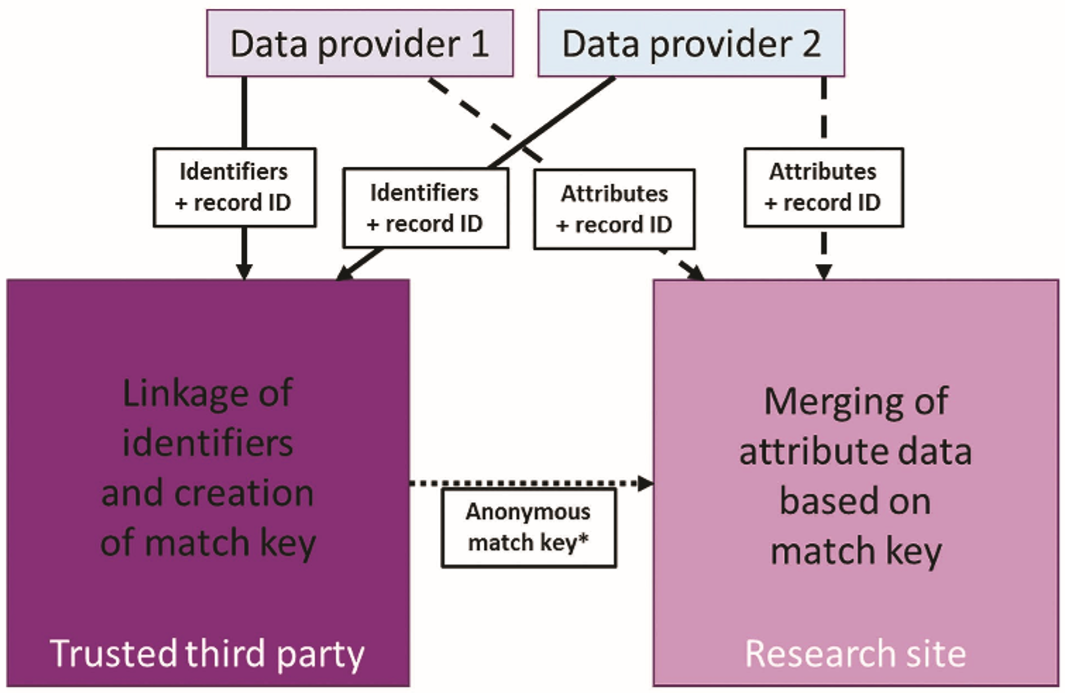
이 시스템은 개인 식별정보와 연구 데이터의 분리를 유지한다. 즉, TTP는 단지 식별정보와 참조번호만을 볼 수 있으며, 연구 데이터를 볼 수 없다. ADRN 직원은 단지 연구 데이터와 색인키만을 볼 수 있을 뿐, 개인 식별정보는 볼 수 없다. 연구자는 보안 시설에서 자신이 요청한 데이터만을 볼 수 있으며, 색인키와 개인 식별정보는 볼 수 없다.
나. 독일 GRLC / FDZ
독일레코드연계센터(GRLC)는 사회과학 분야의 학술 연구를 위해, 행정 데이터를 이용한 데이터 연계 활성화를 목적으로 2011년 설립되었다. 연계 프로젝트별로 원 데이터베이스의 소유권이나 법적 요건이 다르며, GRLC에 데이터 연계를 요청하는 기관이 연계 데이터의 모든 요소에 대한 권한을 갖고 있거나 이용허락을 받았을 경우 연계 데이터 접근에 별다른 제한이 발생하지 않는다. GRLC는 프라이버시를 보호하면서도 효과적으로 데이터 연계를 수행할 수 있는 방법에 대한 연구를 하고 있는데, 이 연구 분야를 프라이버시 보호 데이터 연계(privacy preserving record linkage, PPRL)라고 한다.
독일연방고용국 연구데이터센터(FDZ)는 정부프로젝트 연구자에게 사회보장 및 고용 분야에서 비영리적 실증 연구를 위해 마이크로데이터에 대한 접근을 제공한다. FDZ는 연구자의 데이터 접근을 위해, 현장 이용, 원격 데이터 접근, 학술적 이용 파일 등 세 가지 방법을 제공한다. 이 세 가지 방법은 데이터의 익명화 정도 및 이용조건에서 차이가 있다. 일반적으로 데이터에 대한 접근은 비영리적 연구 목적으로 제한된다.
4) 통계 목적 데이터 연계 현황
가. 미국 Data Linkage Infrastructure
미국은 2016년 3월, 증거기반 정책결정위원회법(Evidence-Based Policymaking Commission Act of 2016)을 통과시켰는데, 관련하여 미국 인구조사국은 평가자 및 정책 분석가의 행정 데이터 접근을 증진하기 위해 데이터 연계기반(Data Linkage Infrastructure)을 확대해 왔다.
인구조사국이 데이터셋을 연계할 경우, 이 연계가 기관의 임무에 부합하려면 가장 좋은 대안(Best Alternative), 공익성, 민감성, 데이터의 기밀성을 고려해야 한다.
데이터 연계기반의 데이터를 사용하기 위해서, 연구자는 우선 제안서를 제출해야 한다. 이 프로젝트가 외부의 데이터를 데이터 연계기반으로 가져올 경우, 프로젝트 제안자는 그 외부 데이터의 이용과 전송을 허가하는 (특히 개인식별정보의 이용을 명시한) 서신을 제출해야 한다. 연구 제안서에 대해서는 학술적인 가치, 실행 가능성, 잠재적인 공개 위험성 등이 평가된다. 인구조사국의 데이터(Title 13) 이용을 요청하는 프로젝트의 경우에는 해당 연구가 인구조사국에 갖는 가치를 입증해야 한다.
행정 기록 프로젝트에 관한 연구자는 현재 인구조사국의 피고용인이거나, 특별선서지위(SSS)를 획득해야 한다. 인구조사국은 자신의 프로그램에 명백히 이익이 되는 작업을 수행하는 개인들에 SSS 자격을 부여하는데, SSS 자격을 가진 개인은 인구조사국 직원과 마찬가지로 평생 데이터를 보호하고 동일한 법적 의무와 처벌을 감수할 것을 선언해야 한다. 인구조사국 직원과 SSS 자격을 가진 개인들은 매년 개최되는 데이터 관리 훈련과 Title 26/연방조세정보 훈련 등 다른 데이터 보유기관이 요구하는 훈련을 받아야 한다. 또한, 관련 윤리, 기밀성, 프라이버시 보호 절차를 준수해야 한다.
제안서의 승인과 훈련이 완료되면, 연방조사국은 보안 컴퓨팅 환경 내에서 접근을 제공한다. 대부분 연방통계연구데이터센터에서 하게 되는데, 마이크로데이터에 대한 모든 분석은 이 컴퓨팅 환경에서 이루어져야 한다. 연구자들은 승인된 데이터 파일의 읽기전용 비식별화 버전에 접근하게 된다.
연구가 마무리된 후, 그 결과물은 공개되기 전에 개인정보나 기업정보가 포함되어 있지 않은지, 결과물이 애초의 제안서와 일치하는지 검토된다. 인구조사국 데이터의 경우, 공개 회피 사무관 혹은 전면공개평가위원회에서 평가를 수행한다. 관련 데이터 보유기관도 결과물을 검토한다.
나. 네덜란드 SSD 시스템
네덜란드 사회통계데이터셋(SSD) 시스템은 상호 연계되고 표준화된 등록소 및 설문조사시스템이다.
허가받은 연구자들이 엄격한 조건 하에, 네덜란드 통계청이 보유한 상세 데이터에 접근할 수 있다. 통계청 구내 장소에서 접근하거나, 보안 인터넷 접속을 통해 원격 접근할 수 있다. 네덜란드 통계청은 네덜란드 통계법과 프라이버시 관련 법률을 준수해야 한다. 개인정보보호법은 애초 수집 목적 외의 개인정보 처리를 금지하고 있지만, 역사적, 통계적, 학술적 목적으로 개인정보를 처리할 수 있는 예외를 두고 있다.
통계법은 개인정보보호를 위한 규정도 포함하고 있다. 이에 따르면, ① 통계청이 받는 모든 데이터는 통계적 목적으로만 사용되어야 한다. ② 통계청은 데이터 보호를 위한 기술적, 조직적 조처를 해야 한다. ③ 공개된 결과물이 개인정보를 드러내지 않도록 조처를 해야 한다. ④ 통계법에 따른 책임을 수행하는 사람을 제외하고는, 다른 사람에게 데이터를 전달해서는 안 된다. 다만, 이에 대한 예외로서, 통계청은 통계적 혹은 학술적 연구 목적으로 다른 기관에 마이크로데이터를 제공할 수 있다.
다. 캐나다 SDLE
캐나다 통계청의 데이터 연계는 마이크로데이터 연계 지침에 따라 이루어지며, 이는 ① 캐나다 통계청 내에서 수행 중인 데이터 수집 및 방법론적 연구의 설계, 유지, 평가, 연구 및 재설계 지원, ② 연구 조사를 지원하기 위한 총계 혹은 익명 형식의 통계 정보 제공이라는 두 가지 목적에서 이루어진다.
캐나다 통계청의 사회 데이터 연계환경(SDLE) 프로그램은 데이터 연계를 위한 환경으로 사회경제적 통계 연구를 촉진하기 위한 목적으로 캐나다 전역에 만들어졌으며 고도로 보안을 갖춘 환경이다. 그러나 SDLE가 거대한 통합 데이터베이스는 아니며 그 핵심인 파생기록보관소(DRD)도 단지 기본적인 개인 식별자만을 가진 동적 관계 데이터베이스이다. 데이터 연계를 위해 사용된 SDLE 식별자와 소스색인파일의 레코드 ID 조합은 키 등록부(Key Registry)에 저장된다.
학술적인 가치 및 연구의 실행 가능성, 적용 방법과 분석될 데이터의 관련성, 상세 마이크로데이터에 접근할 필요성의 입증, 연구자의 전문성과 능력 등의 원칙에 따라 연계 데이터를 요구한 연구에 대해 승인이 이루어진다. 연구 승인 후, 연구에 필요한 특정 집단의 레코드 ID와 이에 연계된 파일들의 관련 레코드 ID가 키 등록부에서 추출된다. 추출한 관련 레코드 ID들이 소스데이터 파일에서 개인의 기록을 찾는 데 사용된다. 이 레코드 ID는 분리된 소스데이터파일로부터 선택된 속성정보들을 추출하여 연계 분석 파일을 만들기 위해 사용된다. 이런 방식을 통해 거대한 통합 데이터베이스를 구축할 필요 없이 가상의 연계환경을 제공하게 된다.
캐나다 통계청은 연구자가 요청하는 데이터의 성격에 따라 다양한 데이터를 제공한다. 공개사용이 가능한 마이크로데이터 파일(PUMFs)의 경우에는 공공기관 및 캐나다 통계청이 협약하는 고등교육기관의 교수와 학생 등에 접근이 가능한데 이 파일들은 개인 수준의 데이터가 없는 익명화된 형태이다. 한편 연구를 위해 연구데이터센터(RDC)가 캐나다 전역에 있는데, RDC 데이터는 총계 처리되지 않은, 개인 수준의 데이터에 대한 접근을 제공한다. 그래서 승인된 프로젝트의 연구자만이 접근할 수 있으며, 연구자들은 통계법상 ‘직원 간주’의 지위를 획득해야 한다. RDC는 캐나다 통계청 직원이 관리하고 있으며, 통계법 조항의 기밀성 규정에 따라 여느 통계청 사무실과 마찬가지로 운영된다. 물리적인 접근이 제한되고, 컴퓨터들은 통계청 외부와 연결되지 않는다.
마이크로데이터에 접근하는 모든 연구자는 캐나다 통계청의 신뢰성 검사를 받고 캐나다 연방 경찰에 보안 검사를 위한 지문도 날인하는 등 보안 절차를 거쳐야 한다. 오리엔테이션을 마친 연구자들은 통계청과 계약을 체결하고 서약한다. 연구자는 캐나다 통계청에 연구결과물을 제출해야 한다.
라. 뉴질랜드 IDI
뉴질랜드 통계청은 자신이 보유한 데이터를 통한 연구를 활성화하기 위해 통합데이터기반(The Integrated Data Infrastructure, IDI)을 운영하고 있다.
IDI는 ① 모든 소스로부터 데이터를 수집하고, ② 수집된 데이터를 처리·연계하며, ③ 비식별화된 데이터를 연구 목적으로 제공한다. 애초 수집 목적 외의 정보 이용에 대해서는 개인정보보호법을 고려해야 한다. 통계법 1975에 상응하거나 제한하는 명백한 법 조항이 있는 경우에는 프라이버시 감독관과 협의해야 한다.
IDI 데이터에 대한 접근은 통계 목적 혹은 공익목적의 순수한 연구 프로젝트에만 허용된다. 연구자들은 자신의 연구 프로젝트에 필요한 데이터에만, 그리고 보안 데이터랩을 통해서만 데이터에 접근할 수 있다. 기밀성 규칙을 보장하기 위해, 연구자가 데이터랩에서 가져가기를 원하는 모든 연구결과물에 대해 검사가 이루어진다.
데이터 통합은 다음의 원칙을 만족할 경우에만 이루어진다. ① 통합으로 인한 공익이 데이터 이용에 대한 프라이버시 우려와 통계 시스템의 무결성, 원 소스데이터, 다른 정부의 활동에 대한 위험보다 커야 한다. ② 통합 데이터는 통계 혹은 연구 목적으로만 사용되어야 한다. ③ 데이터 통합은 개방적이고 투명한 방식으로 수행되어야 한다. 데이터 통합 행위와 결정에 대해 투명해야 하고, 사람들에게 데이터 통합의 목적과 방법을 적극적으로 알려야 한다. 최소한 각 데이터 통합에 대한 정보를 위험 평가정보와 함께 웹사이트에 게시한다. 또한, 사람들에게 자기 정보에 대한 접근권을 보장한다. ④ 응답자에게 통합하지 않을 것이라고 명확하게 약속한 경우에는 통합하지 않는다. 통계청은 원 정보가 어떻게 수집되었는지, 그 정보가 어떻게 사용될지 사람들에게 얘기했는지 파악한다. 다른 기관으로부터 정보를 수집했을 경우, 그 정보가 통계청과 공유될 것이며 단지 분석·통계·연구 목적으로만 사용될 것임을 사람들에게 알리도록 해당 기관에 요청한다.
통계청은 새로운 데이터셋을 IDI 등에 통합하거나 IDI 외부에서 데이터셋을 통합하는 모든 제안에 대해 프라이버시 및 기밀성 영향평가 등을 수행한다. 이 평가를 수행하는 ‘전략, 성과 및 프라이버시 고위 자문관’은 프라이버시 감독기구와 협의할 수 있다.
뉴질랜드 통계청은 마이크로데이터에 대한 접근에 대하여 ‘5가지 안전조치’ 체제를 규정하고 있는데, 이는 데이터 비식별화에 대한 데이터 안전(Safe data)는 물론, 인력 안전(Safe people), 연구 안전(Safe projects), 환경 안전(Safe settings), 결과물 안전(Safe output) 등의 원칙이다.
해외 사례 분석을 통해 공익목적의 데이터 연계를 위한 모범 관행(Best Practice)을 도출할 수 있다. 데이터 연계에 관련한 국제 모범 관행은 데이터 연계라는 특정 절차만이 아니라, 데이터의 수집, 저장, 연계, 제공을 아우르는 원칙과 이를 구현하기 위한 조직적, 기술적인 체계, 즉 데이터 거버넌스 체제를 포함한다. 통계 및 공익 연구 목적의 데이터 이용을 활성화하면서도, 정보주체의 개인정보를 보호하기 위해서는 데이터 거버넌스 전 과정에서 데이터의 활용 및 개인정보 보호조치가 고려되어야 하기 때문이다.
첫째, OECD 2015년 보고서에서 지적한 바와 같이, 데이터 거버넌스 체제를 구축하는 데 있어서 데이터의 이용 및 개인정보보호를 규율하는 법제는 가장 중요한 요소이다.
세계 주요 국가들은 개인정보 처리의 일환인 데이터 연계에 있어, 개인정보보호법제 및 보건의료 관련 법제, 통계 관련 법제에서 개인정보보호, 연구 및 통계와 같은 공익목적을 위한 개인정보의 활용, 개인정보 활용 시 안전조치 등에 관한 규정을 포함하고 있다.
연구 및 통계 목적으로 개인정보를 제공할 경우에, 제안서의 요건, 이용 주체의 자격(승인된 연구기관 혹은 연구자 요건 등), 이용의 조건(안전시설 내에서의 이용, 계약의 체결, 연구결과물의 검토 등)을 보다 구체적으로 법률에 규정하기도 한다.
대다수 국가의 법률들이 투명성을 강조하고 있다. 데이터 제공기관의 정책, 승인이 필요할 경우 그 기준 및 승인 목록 등을 공개하도록 하였다. 또 대부분의 국가 통계법에서는 개별 정보에 접근할 수 있는 사람을 제한하였다.
둘째, 연구의 공익과 프라이버시 보호의 균형을 추구할 수 있는 ‘원칙에 기반을 둔, 비례적인 거버넌스’가 필요하다. 좋은 거버넌스를 위해서 정보 거버넌스 기구, 프로젝트 승인 기구, 연구윤리위원회 등의 기구가 필요한 역할을 수행할 수 있다.
OECD는 이와 같은 검토와 승인 절차의 원칙으로 ‘증거기반(evidence-based)’ 평가가 이루어져야 하고, 객관적이고 공정해야 하며, 적시에 일관성을 촉진하는 방식으로 이루어져야 한다고 권고하였다. 또한, 정보처리가 개인 및 사회에 미치는 편익과 위험성 및 위험성 경감을 평가할 때 전문가들에 의해 독립적이고 학제적인 검토가 이루어져야 한다.
아이슬란드와 덴마크 등 일부 국가에서는 개인정보 감독기구가 연구신청서 승인 기구의 역할을 하고 있다. 프랑스의 경우, 보건 분야에서 공익적인 연구, 조사 혹은 평가를 목적으로 한 개인정보의 처리, 그 목적이 서로 다른 공익을 위한 파일들의 연계 등에 대하여 개인정보 감독기구인 CNIL의 허가를 받고 있다. 이처럼 개인정보 감독기구가 공익목적의 연구 승인 절차에서 일정한 역할을 수행할 필요가 있다.
셋째, 연구 데이터 허브는 데이터를 보유하거나 접근하는 경로로서 역할한다.
데이터 허브는 데이터에 대한 안전한 접근, 이용, 공개에 대한 통제, 검토, 보유, 파기 등의 제반 절차와 관련하여 원 데이터 보유기관 및 규제자와 계약을 체결한다. 개인정보 감독기구는 이 계약에 대해 의견을 제시할 수 있다.
넷째, 데이터 연계의 방식에 있어 개인정보보호를 위하여 ‘신뢰할 수 있는 제3자 색인(TTP)’ 을 비롯한 ‘분리 원칙(separation principles)’을 보장해야 한다.
이는 연계 데이터와 콘텐츠 데이터를 분리하고, 데이터 연계 절차와 데이터 보유 및 추출 기능을 분리하자는 것이다. 데이터 연계를 수행하는 사람은 연구자와 분리되어 있어야 하며, 콘텐츠 데이터 연구에 참여할 수 없다.
다섯째, 해외 모든 연계기관에서는 개인정보보호 및 보안 조치의 중요성을 강조하고 있다.
이는 데이터 비식별화 및 TTP 등 데이터 안전(Safe data)의 개념을 비롯하여 연구 인력(Safe people), 연구 프로젝트(Safe project), 연구 환경(Safe environment/settings), 연구 결과물(Safe results/output)을 포괄하는 보다 폭넓은 개념으로 제안되고 있다.
각국은 공익성을 보장하기 위해 데이터 제공을 받을 수 있는 연구 프로젝트의 조건을 제한하거나, 연구자 때로는 그 소속 기관의 자격요건을 규정하고 있다. 데이터에 대한 접근은 엄격한 보안 시설 내에서 이루어진다. 보통 보안 시설 내 전자기기 등 기록 가능한 매체의 소지가 제한되며 보안시설 바깥으로 데이터셋의 외부 반출도 제한하고 있다. 연구결과물 또한 개인정보 침해가 없도록 공개되기 전에 철저하게 검토하는 절차를 두고 있다. 또 해외 대부분 기관에서는 각 기관과 연구자 사이에 계약을 체결하거나, 이용조건에 동의하도록 함으로써, 연구자들이 개인 식별을 시도하거나 연구 목적 외로 이용하는 등 이용규칙을 위반한 경우에 제재할 수 있는 조처를 하고 있었다.
더불어 해외의 많은 기관이 개인정보 및 보안 조치의 적절성을 검토하기 위하여 프라이버시영향평가를 수행하거나, 각국 개인정보 감독기구와 협의하고 있다.
여섯째, 여러 나라가 연구의 설계, 승인, 안전한 환경 내 데이터 접근을 위해 연구자들을 돕는 연구 지원단을 두고 있다. 연구자들의 데이터 접근을 촉진하는 거버넌스 체제가 발전된 국가들은 연구 지원단을 매개로 하여 데이터 접근에 관련된 정보를 투명하게 공개하고 있다.
일곱째, 공익적 연구 목적을 위한 데이터의 연계나 제공에 대한 대중의 신뢰를 얻기 위해서는 높은 수준의 투명성과 참여가 필수적이다. 원칙과 절차, 진행된 사업 내용에 대한 정보를 투명하게 공개해야 하며, 정책 결정 과정에 시민들과 다양한 이해관계자들이 참여할 수 있도록 해야 한다.
OECD 역시 공공적인 협의 과정을 통해 광범위한 이해관계자들이 관여하고 참여할 수 있어야 한다고 권고하였다. 또한, 정보공개를 통해 개인정보 처리의 목적, 개인정보 처리를 승인하는데 사용되는 절차와 기준, 데이터 거버넌스 체제의 실행 및 그 효과와 관련된 정보를 제공할 것을 권고하였다. 승인된 연구 프로젝트와 관련한 정보를 공개하는 것은 개인정보 이용에 대한 대중의 신뢰를 높일 수 있다. 대중들이 개인정보가 누구에 의해서, 어떤 목적으로, 어떻게 사용되는지 알 수 있기 때문이다. 대중들의 반대 여론에 따라 추진이 중단된 영국의 care.data 사례는 대중적 소통이 얼마나 중요한지 반증하는 사례로 자주 거론된다.
여덟째, 공공데이터를 영리적 목적의 데이터와 연계하는 것은 제한되어 있다. 해외 대부분 기관에서는 연구자에게 개인 수준의 비식별 데이터에 대한 접근 및 연계를 허용하더라도, 개인정보 침해의 위험보다 큰 공익적 가치를 가지는, 혹은 기관 임무에 부합하는 연구로 제한하고 있으며, 이를 위해 연구 프로젝트의 과학적 가치, 실현 가능성, 프라이버시 침해 가능성 등을 기준으로 검토하고 승인을 하는 절차를 거치고 있다.
OECD는 대부분 국가에서 핵심적인 보건의료 데이터셋의 비식별화된 마이크로데이터에 대해 영리적 기업의 접근을 승인하지 않고 있다고 분석했다. 영리 기관에게 데이터에 대한 접근을 승인하는 경우에도, 이는 공익적인 학술 연구나 통계 목적의 이용으로 제한된다. 이때 OECD는 ‘공익(public interest)’의 개념을 데이터 보호, 공공보건, 사회적 보호, 보건의료서비스의 관리, 보건의료 연구 및 통계를 포함하는 것으로 보았다.
국내에서도 통계 및 연구 목적의 행정 데이터 연계 및 접근을 활성화하는 방안을 고려함에 있어, 우선 ‘공익목적’의 연구로 제한하여 신중하게 접근할 필요가 있다.
(3) 국내 데이터 연계·결합 현황
1) 데이터 연계·결합에 대한 국내 법제
가. 데이터 연계·결합 관련 개인정보보호 규율
개인정보자기결정권은 헌법상의 기본권이다. 우리나라 개인정보보호법제의 기본법이자 일반법인 개인정보보호법은 ‘개인정보의 수집, 생성, 연계, 연동, 기록, 저장, 보유, 가공, 편집, 검색, 출력, 정정(訂正), 복구, 이용, 제공, 공개, 파기(破棄), 그 밖에 이와 유사한 행위’를 개인정보의 ‘처리’라고 규정하고 있다(개인정보보호법 제2조 제2호). 이처럼 개인정보의 ‘연계’는 개인정보보호법에서 개인정보 처리의 하나로 명시하고 있고, 결합은 연동과 유사한 개념으로 볼 수 있다. 한편, 개인정보의 연계나 결합으로 인하여 개인에 대한 새로운 정보가 생성되는 것은 개인정보의 수집에 준하는 것으로 볼 수 있다.
처음부터 개인정보를 연계나 결합하는 경우는 당연히 개인정보보호법의 적용대상이 되는데, 애초에는 개인을 식별할 수 없는 정보였는데, 그 정보의 연계나 결합으로 인해서 개인을 식별하거나, 식별 가능성이 생기는 경우에도 연계나 결합으로 인해서 개인정보가 되어 개인정보보호 원칙 및 개인정보 처리에 관한 법률 규정이 적용된다.
개인정보의 처리에 관한 근거로는 크게 ① 개인정보주체의 동의, ② 법률이나 법령의 규정, ③ 공공기관이 업무를 수행하기 위해 불가피한 경우, ④ 기타 적법 요건으로 나누어 볼 수 있으므로 데이터의 연계·결합도 이런 적법 요건을 갖추어야 한다. 개인정보보호법의 적용대상이 되는 데이터 연계·결합 시 정보주체의 권리도 보장되어야 한다.
개인정보인 데이터의 연계나 결합, 연계나 결합의 결과 개인을 식별하거나 식별 가능성이 있는 정보의 연계나 결합을 개인정보보호법 제15조 제1항의 ‘수집’으로 해석한다면 적법한 연계나 결합은 개인정보보호법 제17조 제1항의 각호의 요건에 해당해야만 가능할 것이다.
한편, 데이터의 연계나 결합이 개인정보의 제3자 제공에 해당하는 경우가 있다. 개인정보주체로부터 개인정보 연계나 결합을 하는 것이 아닌 경우이다. 예를 들어 병원에서 수집한 정보주체의 개인정보를 제3자에게 제공하여 그 정보주체에 대한 정보와 결합하도록 하거나, 연계하도록 하는 경우가 여기에 해당한다. 이와 같은 제3자 제공이 적법하기 위해서는 개인정보보호법 제18조 상의 요건을 충족해야 한다.
또 원칙적으로 개인정보처리자는 정보주체에게 이용·제공의 목적을 고지하고 동의를 받은 범위나 개인정보보호법 또는 다른 법령에 의하여 이용·제공이 허용된 범위를 벗어나서 개인정보를 이용하거나 제공해서는 안 된다(제18조 제1항). 예외적으로 개인정보처리자가 목적 외 이용을 하거나, 목적 외로 제3자에게 제공할 수 있으려면 개인정보보호법 제18조 제2항의 요건을 충족하는 동시에 정보주체 또는 제3자의 이익을 부당하게 침해할 우려가 없어야 한다.
특히 개인정보보호법 제18조 제2항 제4호에 따르면 통계작성 및 학술 연구 등의 목적을 위하여 필요한 경우로서 특정 개인을 알아볼 수 없는 형태로 개인정보를 제공하는 경우는 목적 외 이용이나, 제3자 제공이 허용된다.
데이터 결합이나 연계 시 건강정보와 같은 민감정보를 처리하는 것은 개인정보주체로부터 동의를 받거나, 법령에 민감정보의 처리를 요구하거나 허용하는 규정이 있어야만 가능하다. 예컨대 건강에 관한 정보일 경우에는 당사자의 명백한 동의가 있어야 하는데, 별도의 동의가 있어야 한다.
한편, 우리나라 개인정보보호법제는 각 영역별로 특별법이 제정되어 적용 범위가 매우 복잡하게 얽혀 있다. 특히 전자정부법, 공공데이터법의 경우 서로 다른 정책 목표를 가진 법률들이 모순적으로 존재하면서 사실상 개인정보자기결정권의 가치를 훼손하는 경우가 문제가 된다. 조화로운 해석을 통해 개인정보보호에 있어 정합성 있는 법체계를 유지할 필요가 있다.
나. 전자정부법
전자정부법의 경우, 행정의 생산성, 투명성, 민주성, 공동이용의 확대, 중복투자의 방지를 목적으로 하는데, 전자정부서비스라는 개념을 매개로 행정정보 시스템 연계의 근거 규정이 되고 있다.
그런데 전자정부법은 정보시스템의 연계와 관련하여 필요성, 연계정보의 범위, 안전조치 등에 대한 법적 규율이 미비하고 개인정보보호에 대한 구체적인 기준이나, 평가 절차 등이 없어서, 효율성을 이유로 남용될 가능성을 배제할 수 없다. 전자정부법은 행정정보의 공동이용, 전자적 시스템의 연계, 통합 등의 과정에서 개인정보보호법으로 보장되는 개인정보주체의 권리가 침해되지 않도록 하기 위하여 몇 가지 규정을 두고 있지만, 충분하다고 보기 어렵다. 예를 들어 전자정부법은 이용기관이 공동이용센터를 통하여 개인정보가 포함된 행정정보를 공동이용할 때에는 정보주체의 사전동의를 받아야 하고, 이를 개인정보보호법의 동의로 갈음한다. 그런데 알려야 하는 사항이 개인정보보호법의 고지사항보다 축소되어 있고, 매우 포괄적인 동의 예외규정도 두고 있다.
따라서 전자정부법을 개선하여 그 규정들이 개인정보보호법에 의한 정보주체의 권리를 훼손하는 것이 아니라는 점을 명확히 하고 행정의 효율화는 개인정보보호원칙 및 개인정보보호법과 조화를 이루도록 규율을 하는 것이 바람직하다.
다. 공공데이터의 제공 및 이용 활성화에 관한 법률
공공데이터의 제공 및 이용 활성화에 관한 법률(공공데이터법)은, 공공기관이 보유, 관리하고 있는 공공데이터의 제공 및 이용 활성화를 위한 법률이다. 공공데이터법에 따른 데이터의 연계는, 별도로 제공받은 데이터를 제공받은 자가 직접 연계하는 것도 가능할 수 있고, 제공하는 공공기관에서 데이터를 연계하여 제공하는 것도 가능할 것이다.
공공데이터법은 공공기관의 공공데이터에 대해서 적용할 기본 원칙을 규정하고 있는데, 그 내용은 정보공개법이나 개인정보보호법 상의 원칙과 충돌하는 측면이 있다.
공공데이터에는 정부간행물도 포함되지만, 개인의 민감한 건강정보나 형사 처분에 대한 정보 등도 포함되어 있는데, 이를 구분하지 않고 공공데이터로 묶은 상태에서 마치 문화의 향유나 보편적 서비스의 대상인 전기통신 역무와 유사하게 취급하여 ‘이용권의 보편적 확대를 위해 필요한 조처를 할 의무’를 부과하거나, ‘접근과 이용에 대한 평등의 원칙을 보장해야 한다’는 것은 대상별로 적절한 원칙이라 보기 어렵다.
특히 공공데이터법은 비공개 대상정보도 기술적으로 분리 가능하면 분리해서 나머지 정보를 제공하도록 하였는데, ‘기술적 분리 가능성’이 제공대상 공공데이터와 제공불가 공공데이터의 구분 기준이 될 수 없다. 예를 들어 공공데이터로 공개되는 환자 데이터셋의 경우, 개인 식별정보를 기술적으로 분리했지만 다른 정보와의 연계를 통해서 개인을 식별할 수 있으므로 개인정보로 볼 수 있다. 해당 정보를 공개하는 것이 국민의 알 권리 보장을 위해 필요하여 해당 개인의 개인정보자기결정권보다 우월하다면 이를 공개하는 것이 허용될 수 있겠지만, 이를 제공대상 공공데이터로 취급하여 영리적 목적을 불문하고 민간 활용을 촉진하도록 하는 것은 부적절하다.
따라서 정보공개법, 개인정보보호법과 공공데이터법이 모순되지 않도록 규정해야 하고, 특히 공공데이터법은 그 추진체계 및 개인정보의 보호에 관한 규정들이 개인정보보호법에 모순되지 않도록 해야 한다.
라. 데이터기반행정 활성화에 관한 법률
2017년 5월 8일 행정안전부는 「데이터기반행정 활성화에 관한 법률」 제정안을 입법 예고하였다. 주요 제정이유는, 행정·공공기관이 보유하고 있는 대규모 데이터 및 민간 보유 데이터, 인터넷의 공개된 데이터를 분석·활용하기 위한 원칙과 절차를 마련하는 데 있다.
제정안에 대하여 개인정보보호위원회는 개인정보 침해요인 평가를 하였고, 2017년 7월 결정(제2017-15-125호)에서 다음과 같이 개선을 권고하였다. 행정 데이터에는 국민의 민감한 개인정보가 포함되어 있으므로 이를 이용, 제공, 연계하는 경우 국민의 프라이버시를 침해할 위험이 크므로 정보주체의 명확한 동의를 기반으로 하는 것이 바람직하며 「개인정보 보호법」의 제 규정을 준수해야 한다. 다만 대량의 행정 데이터를 개별적인 동의를 받아 처리하기 어려운 현실적 제약과 행정 데이터 연계를 통해 얻을 수 있는 공공의 이익을 고려하여 「개인정보 보호법」 제18조 제2항 제4호 등에 따라 개인을 알아 볼 수 없는 형태로 데이터 연계를 추진하는 것이 공익을 위해 필요한 것으로 보인다. 그러나 이 경우에도 프라이버시 침해 위험으로부터 개별 국민을 보호하기 위해 「개인정보 보호법」에 따른 명확한 근거가 필요하고 적정한 관리·감독체계 구축, 데이터 처리에 있어 완전한 기능 분리를 통한 개별 국민의 프라이버시 보호와 인적·물적·기술적·관리적 조치를 통한 데이터의 안전성을 확보하여야 하며 연계대상 행정 데이터의 내역 및 연계절차를 국민들이 알 수 있도록 투명하게 공개할 필요가 있다.
이상과 같은 개인정보보호위원회의 권고 내용은 행정 데이터 연계의 공익과 개인정보 보호법에 따른 정보주체의 권리를 조화시키고, 영국 디지털경제법 등 데이터 연계절차에 대한 국제 모범 사례를 참고하여 이를 국내 관련 입법안에 적절히 반영토록 한 것으로 평가할 수 있다.
2) 국내 보건의료 분야 데이터 연계 현황
개인 병력이나 질병, 건강상태 등에 관한 정보는 가장 민감한 정보로서, 이 정보는 공개될 경우 개인에 대한 사회적 낙인이 될 수도 있고, 고용, 보험은 물론 사회생활에서 차별의 원인이 될 수도 있고, 개인의 민감한 사생활 침해가 될 수도 있다. 의료법, 약사법 등에서도 진료기록과 처방에 대한 기록을 엄격하게 보호하고 있다.
우리나라는 OECD 국가 중 건강정보 수집, 집적, 연계가 높은 수준이다. 치료 목적, 건강보험의 운영 및 관리 목적, 연구 목적, 보건 정책의 평가와 의료서비스의 질 관리 목적 등 다양한 목적으로 건강정보의 연계나 결합이 이루어지고 있다.
문제는 현재 이루어지고 있는 대다수 보건의료정보의 수집, 활용의 경우 사전동의나 법률 규정을 찾기가 어렵다는 점이다. 개인정보보호원칙이 적용되어 관리되고 있다거나, 충분한 거버넌스 구조를 갖추고 있다고 보기도 어렵다.
부득이한 경우 당사자의 동의가 없어도 개인건강정보를 활용한 공익적 목적의 연구가 필요하다는 점은 인정되지만, 현재 법령에 특별한 규정이 없다. 따라서 공익적 목적의 연구와 관련해서는 반드시 필요한 경우 부득이하게 해당 개인의 동의를 받을 수 없을 때 건강정보를 활용하여 연구할 수 있는 규정과, 연구와 관련한 개인정보의 활용과 관련한 안전조치 등을 법제화할 필요가 있다.
가. 건강정보의 수집·이용 관련 법제
개인정보 중 민감정보에 해당하는 건강정보의 수집, 이용, 제공, 보관, 연계나 결합 등에 대해서는 개인정보보호법이 적용되므로, 개인정보보호법 제23조에 따른다. 즉, 민감정보의 처리는 원칙적으로 금지되고, ① 정보주체에게 고지할 사항을 알리고 다른 개인정보의 처리에 대한 동의와 별도로 동의를 받은 경우이거나, ② 법령에서 민감정보의 처리를 요구하거나 허용하는 경우에만 처리가 허용된다.
그리고 민감정보의 수집, 처리 시에는 당사자의 동의를 받았거나 법률의 규정이 있다고 하더라도 최소수집의 원칙, 익명 처리의 원칙 등 개인정보보호 원칙과, 정보를 제공받을 권리, 접근권, 열람 및 정정, 삭제, 처리중지 요구권, 철회권 등 정보주체의 권리가 보장되어야 하고, 침해 시에는 권리구제를 받을 수 있다.
의료기관, 약국, 정신보건기관 등은 치료, 조제 등의 과정에서 환자로부터 방대한 양의 건강정보를 수집하고, 처리한다. 이 정보들은 국민건강보험공단, 심사평가원, 국립암센터 등을 통하여 수집되기도 하고, 데이터 연계 등 2차적 활용으로 이어진다.
의료기관, 약국, 정신보건기관 등의 경우 법령상 기록 작성과 보관의무가 부과되어 있는데, 그 대상 기록은 정신보건법에 의한 진료기록부, 의료법에 의한 처방전, 조산기록부, 간호기록부와 약사법에 의한 조제기록부 등이다. 이 경우는 정보주체의 동의를 받지 않고도 해당 건강정보를 기록하고, 보존할 수 있다. 그 외의 의무기록은 당사자로부터 명시적인 동의를 받아야 할 것이다.
의료법, 약사법, 정신보건법 등은 의료인, 약사 등에 대해서 엄격한 비밀준수 의무를 부과하고 있다. 아울러 의료인, 의료기관의 경우는 환자에 관한 기록, 조제기록부의 정보를 다른 사람에게 열람하게 하거나, 사본을 내주는 등 내용을 확인할 수 있게 하는 행위를 법률에 명시된 경우 외에는 금지하고 있다. 형법도 업무상비밀누설죄로 직무상 알게 된 비밀의 누설이나 공표를 엄격하게 규율하고 있다. 다만 의료법과 약사법은 환자 정보를 당사자의 동의가 없어도 제3자에게 제공할 수 있는 예외를 한정적으로 열거하고 있는데, 그중 가장 대표적인 것이 국민건강보험, 의료급여의 비용심사, 지급대상 여부 확인, 사후관리, 적정성 평가, 가감지급을 위하여 건강보험공단, 건강보험심사평가원으로 제공하는 경우이다.
의료인이나 의료기관이 환자의 건강정보를 활용하여 연구하고자 할 경우에는 그에 대한 명확한 동의를 얻어야 한다. 아울러 개인정보가 식별될 수 있는 경우 등 필요한 경우에는 생명윤리법에 의한 심의를 거쳐야 한다. 연구 목적으로 개인정보를 활용하면서 데이터의 연계·결합하려고 하는 경우에도 마찬가지이다.
한편, 연구에 활용하는 경우에도 그 자체의 정보뿐만 아니라 다른 정보와 결합하여도 개인을 식별하는 것이 불가능한 정보를 활용하는 경우에는 해당 정보는 개인정보로 볼 수 없을 것이므로 해당 정보주체로부터 동의를 얻을 필요는 없다.
환자와 의료기관 사이 건강정보의 수집, 이용 및 데이터 연계 등에 있어, 현행 의료법, 약사법, 정신보건법 등의 규정에서 건강정보의 수집 근거를 명확히 하고, 개별 의료기관에서 동의를 구할 때는 정보 수집 시 민감정보 수집을 별도로 고지하고, 수집항목, 보유 기간, 제3자 제공 등에 대해서 분명하게 명기한 표준 동의서 등을 작성하는 등 제도개선이 필요하다.
건강정보의 2차적 수집 및 활용의 경우로는 국민건강보험공단, 건강보험심사평가원 등이 의료기관으로부터 수집하여 보유하고 있는 건강정보, 보건의료 통계나 조사자료, 질병관리본부의 연구 목적 건강정보, 암 등록정보, 전염병 정보, 건강검진 정보 등을 들 수 있다.
그러나 의료기관으로부터 건강보험공단, 건강보험심사평가원 등이 수집 및 활용, 질병관리본부, 국립암센터 등이 수집하는 정보 및 그 2차적 이용에 대해서는 법적 근거가 매우 미비한 상황이다.
특히 민감정보는 법령에서 구체적으로 민감정보의 종류를 명시하여 처리의 근거를 규정해야 한다.
우리나라는 의료 사회보장제도 운영에 따라 국민건강보험, 의료급여, 노인장기요양보험, 산업재해보험 등에서 건강정보의 수집 및 이용이 이루어지고 있다. 국민건강보험공단은 산업재해보험을 제외한 이들 사회보험에서 의료기록을 제공받고, 이용하고 있다.
나. 의료 사회보장제도와 데이터 연계
가) 국민건강보험공단의 건강정보 수집, 활용과 데이터 연계
국민건강보험공단은 건강보험과 노인장기요양보험의 보험자, 의료급여의 수탁기관, 국민건강증진기관으로서 역할을 수행하는 과정에서 (i) 가입자 및 피부양자의 자격 관리를 위해 필요한 자료, (ii)보험료 부과, 징수를 위해 필요한 자료, (iii) 보험급여의 관리를 위해 필요한 자료, (iv) 보험급여 비용의 지급을 위해 필요한 자료, (v) 건강 증진과 예방사업을 위해 필요한 자료를 광범위하게 수집하게 된다.
(i) 국민건강보험공단은 국민건강보험법, 노인장기요양보험법과 의료급여법에 의하여 가입자 및 피부양자, 수급자의 자격 관리를 업무로 관장하도록 수권을 받았기 때문에, 이를 근거로 가입자, 수급자 자격 관리를 위해서 다양한 정보를 수집하고 대부분 영구로 보관한다.
현재 자격정보를 다른 정보와 연계하거나, 결합하는 것과 관련해서는 법령에 구체적 규정은 없다. 다만, 국민건강보험공단이 공개한 개인정보파일에서는 다른 정보시스템과 연계하고 있다고 밝히고 있다. 그러나 구체적으로 어떤 정보시스템과 연계하고 있는지에 대해서는 밝히지 않고 있다.
자격정보 수집과 관련하여 다음과 같은 제도개선이 필요하다. ① 수집하는 정보의 범위를 법령이나 고시 등으로 규율하고, 공개할 필요가 있다. ② 수집하는 정보는 자격 정보로써 필요한 최소한의 범위로 한다. ③ 보유 기간은 목적 달성에 필요한 최소한의 기간으로 하여, 목적 달성 후 즉각 폐기하도록 한다. ④ 보유 기간을 법령이나 고시 등으로 명확하게 규율하는 것이 바람직하다. ⑤ 자격정보를 자격 확인 외의 목적으로 활용하는 것은 목적 외 활용으로 부당하다. 예를 들어 자격정보를 취업 후 학자금 상환 특별법에 따라 국세청에 제공하도록 하는 것은 그 타당성을 수긍하기 어렵다. ⑥ 자격정보에 대한 개인정보 처리방침 등 개인정보의 처리에 관한 사항을 공개하고, 개인정보주체의 열람권, 정정권 등을 보장하여 개인정보의 정확성, 완전성 및 최신성이 보장되도록 하여야 한다. ⑦ 개인정보처리자는 정보주체의 사생활 침해를 최소화하는 방법으로 개인정보를 처리하고, 개인정보의 익명 처리가 가능한 경우에는 익명에 의하여 처리될 수 있도록 하여야 한다.
(ii) 국민건강보험공단은 보험료, 장기요양보험료의 부과 및 징수를 위해서도 방대한 자료를 수집한다. 직장의료보험 가입자의 경우에는 직장과 소득에 대한 상세한 자료, 지역의료보험 가입자인 경우는 재산이나 소득에 대한 상세한 자료를 수집하고 대부분 준영구로 보관한다.
현재 보험료 부과, 징수 정보를 다른 정보와 연계하거나, 결합하는 것과 관련해서도 법령에 구체적 규정은 없다. 다만 국민건강보험공단이 공개한 개인정보파일에서 다른 정보시스템과 연계하고 있다고 밝히고 있지만, 역시 구체적으로 어떤 정보시스템과 연계하고 있는지에 대해서는 밝히지 않고 있다.
보험료 부과, 징수와 관련된 정보 수집과 관련하여 다음과 같은 제도개선이 필요하다. ① 수집하는 정보의 범위를 법령이나 고시 등으로 규율하고, 공개할 필요가 있다. ② 수집하는 정보는 자격 정보로써 필요한 최소한의 범위로 한다. ③ 보유 기간은 목적 달성에 필요한 최소한의 기간으로 하여, 목적 달성 후 즉각 폐기하도록 한다. ④ 보유 기간을 법령이나 고시 등으로 명확하게 규율하는 것이 바람직하다. ⑤ 보험료 부과, 징수에 관한 정보를 보험료 부과. 징수 목적 외의 목적으로 활용하는 것은 부당하다.
(iii) 보험급여(의료급여) 관리 및 (iv) 비용지급과 관련하여, 우리나라 건강보험이나 의료급여는 모든 진료 행위에 대한 상세한 내역이 제공되어야만 보수를 산정할 수 있으므로, 요양기관은 그에 대한 상세한 정보를 국민건강보험공단과 심사평가원에 모두 제공해야만 한다. 요양급여비용 청구명세서 정보는 5년 보존되지만 5년 후에도 삭제하지 않고 국민건강DW정보에 보유되며, 요양급여내역 등의 정보는 5년 또는 10년씩 보유되고, 상해 등 고의 또는 중대한 과실의 경우에는 사고발생경위, 사법기관에서 제공받은 처분결과, 가해자 성명 등에 대한 정보를 수집하여 준영구 보유하고 있다.
현재 요양급여 청구정보 등과 다른 정보를 연계하거나, 결합하는 것과 관련해서는 법령에 구체적 규정이 없는데, 국민건강보험공단은 다른 정보시스템과 연계하고 있다고 밝히고 있다. 구체적으로 어떤 정보시스템과 연계하고 있는지에 대해서는 밝히지 않고 있다.
보험급여(의료급여) 관리 및 비용지급과 관련하여 다음과 같은 제도개선이 필요하다. ① 수집하는 정보의 범위를 법령이나 고시 등으로 규율하고, 공개할 필요가 있다. ② 수집하는 정보는 자격 정보로써 필요한 최소한의 범위로 한다. ③ 보유 기간은 목적 달성에 필요한 최소한의 기간으로 하여, 목적 달성 후 즉각 폐기하도록 한다. ④ 보유 기간을 법령이나 고시 등으로 명확하게 규율하는 것이 바람직하다. ⑤ 보험료 부과, 징수에 관한 정보를 보험료 부과. 징수 목적 외의 목적으로 활용하는 것은 부당하다.
(v) 국민건강보험공단은 건강증진과 예방 등의 업무로 전 국민에 정기적으로 건강검진을 하고 이 과정에서 사실상 전 국민의 정기적인 건강검진 자료가 국민건강보험공단에 수집되어 영구 보관된다. 다만 만성질환자와 전단계자에 대해서는 사후관리대상자로 별도로 관리하고 있다(10년).
현재 건강검진 정보 등을 다른 정보와 연계·결합하는 것에 관해서는 법령에 구체적 규정은 없다. 다만, 국민건강보험공단이 공개한 개인정보파일에서는 다른 정보시스템과 연계하고 있다고 밝히고 있고, 건강검진대상자 및 검진결과 내역의 경우, 영구적으로 보유하면서 보건복지부, 국립암센터, 사회보장기관에 정보를 제공하여 연계하고 있다. 그 외에 어떤 정보와 연계하고 있는지에 대해서는 밝히지 않고 있다.
건강검진 자료수집과 관련하여 다음과 같은 제도개선이 필요하다. ① 수집하는 정보의 범위를 법령이나 고시 등으로 규율하고, 공개할 필요가 있다. ② 수집하는 정보는 필요한 최소한의 범위로 한다. ③ 보유 기간은 목적 달성에 필요한 최소한의 기간으로 하여, 법령이나 고시로 명시하고, 목적 달성 후 즉각 폐기하도록 한다. ④ 데이터의 연계, 제3자 제공 등을 엄격하게 제한해야 한다.
나) 건강보험심사평가원의 건강정보 수집, 활용
건강보험심사평가원은 의료공급자가 진료비를 청구하면 국민건강보험법 등에서 정한 기준에 의해 진료비와 진료 내역이 올바르게 청구되었는지, 의·약학적으로 타당하고 비용 효과적으로 이루어졌는지 확인한다. 이 과정에서 건강보험심사평가원은 방대한 양의 건강정보를 수집, 처리한다. 심사평가원이 수집하는 정보는 범주를 나누어 보면, ① 진료정보, ② 의약품 정보, ③ 치료재료 정보, ④ 의료자원 정보, ⑤ 비급여 정보, ⑥ 평가정보로 나누어 볼 수 있다.
진료비 심사 청구에 관한 정보는 당해 목적의 범위에서 보유하는 것이 바람직한데, 준영구로 보유하는 것은 문제이다. 따라서 청구명세서의 항목도 필수 불가결한 것으로 검토하여 제도를 개선하는 것이 바람직하다.
다) 건강보험의 건전성 유지, 연구 목적 2차적 이용
국민건강보험공단은 보험급여의 관리, 건강보험에 관한 조사연구, 건강관리 사업을 업무로 담당하도록 법률에 규정되어 있다. 현재 국민건강보험공단은 이를 근거로 연구 목적이나 2차적 이용을 목적으로 다양한 정보를 연계·결합하여 활용하고 있다.
(i) 국민건강정보 데이터베이스
국민건강보험공단은 현재 40,833,684,272명의 개인에 대한 건강정보를 삭제하지 않고 보유하고 있다고 한다. 국민건강보험공단은 이 정보 파일에 대해서 ‘전 국민의 자격 및 보험료, 건강검진결과, 진료내역, 노인장기요양보험 자료, 요양기관 현황, 암 및 희귀난치성질환자 등록정보 등 1조 3천억 건에 달하는 방대한 빅데이터를 말한다’고 설명하고 있다.
국민건강보험공단이 보유한 △건강보험 적용인구, 세대정보 △사업장 및 지역보험료 부과 정보, 징수, 체납정보 △일반건강검진, 암 검진, 생애 전환기 검진 △노인장기요양 인정신청 및 급여 △요양급여비용 지급 및 중증암환자 등록, 현금급여 지급 △의료급여 적용, 세대, 급여비용 등의 정보는 주민등록번호나 건강보험증번호와 같이 고유식별정보를 모두 포함하고 있어서 다른 정보와의 연계도 가능하다. 아울러 이 정보는 국민건강보험공단이 자격정보, 징수 정보, 심사 청구 명세서 정보, 요양급여내역, 건강검진정보, 희귀질병 정도 등 국민건강보험공단이 각각 다른 목적으로 수집하여 보유하고 있는 정보를 연계한 것으로 보인다.
그런데 다양한 목적으로 국민건강정보 데이터베이스로 수집된 개인의 건강정보와 자격정보, 징수 정보 등의 개인정보가 연계·결합되고, 이용, 제공되는 것에 대하여 해당 개인에게 동의를 받은 사실이 없다. 따라서 법적 근거가 있어야 하는데 국민건강보험법 제14조 제1항 제9호에서 국민건강보험공단의 업무로 ‘건강보험에 관한 조사연구 및 국제협력’이 규정되어 있지만, 이 규정을 개인정보보호법 제23조 제1항의 ‘민감정보의 처리를 허용하는 법령의 규정’으로 보기에는 난점이 있다.
2차적 이용과 관련하여 다음과 같은 제도개선이 바람직하다. ① 연구 목적의 건강정보 활용을 위해서는 개인정보주체의 동의가 없는 한 현재의 국민건강보험법에 의한 개인정보 활용은 적법한 근거라고 보기 어렵다. ② 모든 개인의 건강정보를 포괄적으로 연계하여 준영구로 보유하는 것은 개인정보보호원칙을 위반한다. ③ 연구 목적의 건강정보 활용을 하려면 연구 목적에 필요한 최소한의 정보를 보유하고, 폐기해야 한다. ④ 연구 목적의 건강정보 활용을 위해 최소한의 정보를 활용하더라도 익명화 등 안전조치를 취하는 것이 바람직하다.
(ii) 5종의 코호트 DB
국민건강보험공단은 5종의 코호트 정보를 연구 목적으로 생성하여 보유, 활용하고 있는데, 코호트 정보는 개인에 대한 추적정보이기 때문에 그 민감성이 더욱 크다.
규모가 가장 큰 전 국민 표준코호트DB의 경우 전 국민의 2%에 달하는 100만 명을 추출하여, 무려 14년간의 사회, 경제적 현황과 장애, 사망, 의료이용 현황, 모든 진료내역은 물론, 건강검진 등의 상세한 정보(자격 및 보험료, 출생 및 사망, 모든 진료내역, 건강검진 내역)를 데이터베이스로 구축한 것이다. 또 건강검진 코호트 DB는 수검자 중 10%, 노인 코호트는 대상자 중 10%, 직장여성 코호트 DB는 5%, 영유아검진 코호트 DB 5%를 추출하는 등 그 대상도 방대하고, 코호트 정보를 추적하여 축적한 기간이 14년 ~ 8년간으로 장기간인 데다가, 수록 정보도 사회경제적인 정보와 의료와 건강검진 정보까지 포괄하고 있어서 개인의 내밀한 사생활까지 고스란히 담겨져 있다.
5종의 코호트 DB의 보유 목적은 연구 목적이라고 밝히고 있다. 일반적으로 코호트 연구는 당사자의 동의를 받아서 진행한다. 그러나 국민건강보험공단은 어디에서도 당사자들에게 동의를 받았다는 정보나 받은 동의의 내용을 밝히고 있지 않다. 그뿐만 아니라 해당 정보주체에게 코호트DB로 해당 정보주체의 여러 가지 정보가 연계되어 추적, 축적되어 있고, 그 정보들이 제3자에게도 제공되고 있다는 점에 대해서 알리고 있지 않은 것으로 보인다. ‘건강보험에 관한 조사연구’(국민건강보험법 제14조 제1항 제9호)를 법적 근거로 보기도 어렵다. 국민건강보험공단은 코호트 자료를 만들면서 소위 ‘비식별 조치’를 했다고 하지만 이는 가명화와 그룹핑, 민감 상병의 마스킹 수준으로, 개인정보보호법의 적용이 배제되는 ‘개인을 알아볼 수 없게 조치한 것’으로 보기는 어렵다.
(iii) 건강보험심사평가원의 DW시스템, 빅데이터 분석 DB 등
건강보험심사평가원은 심사기준 및 평가 기준의 개발, 그에 따른 업무와 관련된 조사연구 및 국제협력, 요양급여비용의 심사 청구와 관련된 소프트웨어의 개발·공급·검사 등 전산 관리, 환자 분류체계의 개발·관리 등의 업무를 담당하는데, 이를 위하여 건강정보를 활용할 수 있는지가 문제 된다.
건강보험심사평가원은 DW시스템(명세서), 빅데이터 분석 DB 등의 정보를 준영구로 보유하고 있다고 한다. 이 정보들은 데이터 연계로 축적되고 있는 것으로 보인다. DW 시스템이라는 명목으로 139억명의 민감한 건강정보를 준영구로 보유하고, 5,300만 명의 빅데이터 분석 DB를 보유하는 것은 법적 근거를 찾기 어렵고, 개인정보보호원칙에 어긋나는 것으로 문제이다.
(iv) 건강보험심사평가원의 환자데이터셋
건강보험심사평가원은 2009년부터 매년 1년간 진료받은 환자를 대상으로 표본 추출을 하여 환자데이터셋이라는 이름으로 공개를 하고 있다. 입원환자 데이터셋은 입원환자의 13%에 달하는 100만 명 정도, 전체 환자 데이터셋은 전체 환자의 3%인 140만 명, 고령환자 데이터셋은 전체 고령환자(60세 이상)의 20%인 100만 명 정도, 소아청소년환자데이터셋은 소아청소년환자(20세 미만)의 10%인 약 100만 명 정도의 환자데이터셋을 매년 추출하여 작성하는 것이다.
환자데이터셋에 대해서 주민등록번호를 대체키로 변환하고, 가명처리, 데이터삭제, 마스킹 등의 조치를 했다고 한다. 그런데 이와 같은 비식별 조치로는 환자 정보의 일부를 가지고 있거나, 언론, 소셜미디어 등의 정보와 결합하는 경우 재식별이 가능할 수 있다.
공공데이터로 개방하여 공개하기 위해 구축된 환자데이터셋은 민감한 개인정보이므로 이를 연계하려면 해당 환자로부터 그와 같은 개인정보의 연계에 대해서 명시적인 동의를 받거나, 법적 근거가 필요하다. 건강보험심사평가원은 ‘공공데이터의 제공 및 이용 활성화에 관한 법률’에 근거하여 비식별 조치를 했으므로 제공할 수 있다고 보았다. 그러나 공공데이터법이 제공의 근거가 될 수 없으며, 비식별 조치라는 것은 개인을 식별할 수 있는 정보로서 개인정보보보헙 제23조의 규율 대상이 된다. 따라서 그에 대한 명확한 법적 규율이 없는 한 민감한 개인정보인 건강정보의 제공은 허용되지 않는다.
라) 보건의료 빅데이터 개방시스템을 통한 데이터의 연계
보건의료 빅데이터 개방시스템으로 국민건강보험공단은 국민건강보험자료 공유서비스를, 건강보험심사평가원은 보건의료빅데이터 개방시스템을 운영하고 있다.
(i) 국민건강보험공단의 국민건강보험자료 공유서비스
국민건강보험공단은 국민건강보험자료 공유서비스를 통해 자신이 수집·보유·관리하는 건강보험 및 장기요양보험 관련 자료를 학술연구 및 정책연구 목적으로 제공하고 있다. 표본연구 DB 외에도 맞춤형 자료의 경우 외부 기관 자료와 연계 서비스도 제공하고 있다. 그러나 현행 법령상 건보공단이 제공받은 자료를 계속 보유하면서 개인정보를 연구에 제공할 수 있는 법적 근거는 희박해 보인다.
(ii) 건강보험심사평가원의 보건의료빅데이터 개방시스템 운영
건강보험심사평가원은 심사평가 등의 업무와 관련하여 수집, 보유하고 있는 국민의 건강정보를 ‘공공데이터의 제공 및 이용 활성화에 관한 법률’의 ‘공공데이터’로 보고, 보건의료빅데이터개방시스템을 통하여 개방하고 있다.
자료제공대상은 의료기관 종사자, 학술 연구 수행기관, 제약업체 및 의료기기 업체 등 산업계는 물론이고, 컨설팅업체 및 예비 창업자 등도 포함하고 있다. 영리 여부를 불문하고, 누구에게나 개방하며, 실제로 민간보험회사에도 국민의 진료내역 등을 제공하였음이 밝혀지기도 했다.
진료정보, 의약품 정보, 치료재료정보, 의료자원정보 외에도 맞춤형 자료의 경우, 요청되는 정보들이 특정한 상병이나 특정한 약품 수진자 전부에 대한 정보 등 충분히 개인이 식별될 수 있는 정보들이다.
현재 보건의료빅데이터 개방시스템에서는 과제목록을 공개하고 있는데, 전체 625건의 과제 중 공개하고 있는 것은 단 2개에 불과하고, 나머지는 모두 비공개로 신청하고 있다.
연구자는 외부기관의 자료를 연계하기도 하는데, 외부기관의 자료원을 개인의 고유식별정보를 이용하여 심사평가원의 청구자료와 연계하여 분석을 수행하고자 할 경우, 외부기관이 민감정보, 고유식별정보, 주민등록번호를 심사평가원에 제공하기 위해서는 제3자 제공에 대한 법적 근거가 있어야 한다. 개인정보보호법과 생명윤리 및 안전에 관한 법률에 따른 서면 동의를 받고, 기관위원회의 심의를 받아야만 민감정보, 고유식별정보, 주민등록번호 처리가 가능하고, 제3자에게 제공이 가능하다.
다. 기타 건강정보와 데이터 연계
법률적 의무를 부과하는 암 정보 등록제도에 대해서는 그 필요성이 인정된다. 그럼에도 국립암센터와 지역의 대학병원들이 암 등록사업을 수행함에 있어서 환자들의 암 관련 정보들이 개인정보보호법 적용대상에서 제외되고, 통계법에는 통계자료의 비밀보호 규정이 미비하고, 암관리법도 비밀보호규정이 미비하기 때문에 암 등록사업의 비밀보호와 개인정보보호가 충분하다고 보기 어렵다.
암관리법은 보건복지부장관 요구하는 ‘암등록통계사업에 필요한 자료’의 제출(암 환자의 진료와 관련된 자료 및 의무기록 등)이나 의견의 진술에 있어 그 수집대상 정보가 무엇이고 요구 상대방이 누구인지를 명확하게 규율하고 있지 않다. 또 보건복지부장관이 자료나 의견 진술을 요구할 경우 자료제출을 요구받은 자는 특별한 사유가 없으면 요구에 따라야 한다는 규정을 두고 있는데, 환자 본인의 거절권이 보장되는 것이 바람직하다. 특히 암 정보는 매우 민감한 정보이고 유출되는 경우 해당자의 고용, 보험 등 사회생활에서 차별과 불이익이 우려되므로 암등록통계사업은 명확하게 규정된 법령에 따라서 이루어져야 한다. 또 암등록통계사업을 위해 수집한 환자들의 암 관련 정보들은 암등록통계사업의 목적으로만 활용될 수 있도록 규정할 필요가 있다. 수집된 정보는 개인정보보호법이 적용 배제되고 개인정보보호 관련 규정이 매우 미비한 통계법만 적용되는데 특히 비밀보호에 대한 개인정보보호 규정의 보완이 필요하다.
한편 중앙암등록본부의 자료는 통계법의 적용대상이 되므로, 비밀보호의 대상이 되고, 통계나 연구 목적 외의 목적으로 활용되어서도 안 된다. 다만 현재 중앙암등록본부에 등록된 원시자료 및 주문형 자료는 개인정보보호법 및 의료법 제20조에 준하여 ‘등록환자의 개인정보가 보호될 수 있는 범위 내에서 제공하고 있다’고 하는데, 어느 정도의 비식별 조치를 했어야 ‘개인정보가 보호될 수 있는 범위’가 될 수 있는 것인지는 논란이 된다. 의료정보의 경우는 비식별화를 하더라도 일부의 주소, 초진 연월일, 입원일, 퇴원일, 치료시행 여부, 진단경로, 원발부위, 전이부위, 조직학적 진단명, 진단방법, 병기 분류, 분화도, 사망연월일, 사망원인 등의 자료만으로도 특정인을 식별해 낼 수 있다.
국립암센터는 암관리법의 암등록통계사업, 암 검진사업, 암 환자의 의료비 지원사업 등, 완화의료 사업 등 4개 사업별 DB를 연계, 통합하여 통합 데이터베이스로 구축하고, 이를 활용해 시범서비스를 개발하고 있다. 그러나 이와 같은 4개 사업 DB의 연계, 구축에 대한 적법한 근거가 부족하다. 또 국민건강보험공단과 국립암센터는 공동연구 협약을 체결하고, 국립암센터 암 등록자료, 건강보험공단 암 환자 자료, 통계청 사망자료 등 연계를 통하여 암 진단 및 치료 효과, 국가 암 관리사업 효과 평가 등을 수행하고자 관련 자료의 수집 및 연계와 분석 적합성 점검을 진행하였다. 그런데 이와 같이 대규모로 민감한 건강정보를 연계하는 것과 관련하여 법적 근거가 미비하다. 비록 암 관련 연구 과제의 해결이 중요하기는 하지만, 10여 년간의 민감한 개인정보가 환자에게 아무런 선택권도 없이 통합되어 만들어졌다는 것은 문제의 소지가 있다.
암 등록사업의 필요성을 인정하더라도 암 등록자료는 개인의 민감정보에 해당한다. 따라서 해당 정보주체의 동의 없이 민감한 개인정보를 연구 목적으로 제공하는 것은 적법한 법적 근거를 갖출 필요가 있다.
라. 인간대상연구 등 개인정보 활용 연구
생명윤리법에서 규율하는 인간대상연구와 인체 유래물 연구도 연구의 대상이 되는 정보가 개인정보에 해당할 가능성이 크다. 생명윤리법은 연구대상자의 보호를 위한 조치로 피험자의 권리와 안전에 대한 고려, 불완전 능력자와 취약계층에 대한 보호, 개인정보보호 및 기록의 유지와 정보공개 원칙 등을 규정하고 있다. 또 인간대상연구를 하려는 자나 인체 유래물 연구를 하려는 자는 연구를 하기 전에 연구계획서를 작성하여 기관위원회의 심의를 받아야 한다.
인간대상연구, 인체 유래물 연구를 하기 전 연구대상자, 기증자로부터 서면 동의를 받는 것이 원칙이다. 다만 ① 연구대상자의 동의를 받는 것이 연구 진행과정에서 현실적으로 불가능하거나 연구의 타당성에 심각한 영향을 미친다고 판단되는 경우로서, ② 연구대상자의 동의 거부를 추정할 만한 사유가 없고, 동의를 면제하여도 연구대상자에게 미치는 위험이 극히 낮은 경우 서면 동의를 면제할 수 있다.
제3자 제공의 경우 기증자나 연구대상자로부터 인체 유래물 및 개인정보 제공에 대하여 서면 동의를 받은 경우 기관위원회의 심의를 거쳐 인체 유래물 은행이나 다른 연구자 등에 제공이 가능하다. 이때 기증자 및 연구대상자가 개인식별정보를 포함하는 것에 동의하지 않았다면 익명화를 해서 제공해야 한다. 연구자는 이에 대한 기록을 작성, 보관해야 한다.
3) 국내 통계 분야 데이터의 연계 현황
통계 분야에서도 데이터 연계·결합의 요구가 늘어나고 있다. 통계청은 빅데이터 활용을 주요 과제로 선정하고 있다. 통계와 관련한 법제로도 개인정보보호법과 통계법이 있고, 각 부처의 훈령으로 통계관리규정을 두고 있지만, 다양한 데이터 연계와 통합, 특히 민간분야와의 연계 등을 시도하는 상황에서 그에 대한 규율이 매우 미흡하다.
가. 통계 제도와 기본 원칙
우리나라 통계법은 제2조와 제33조에서 통계의 비밀보호에 대해 규율하고 있다. 그런데 이 규정은 ‘비밀’에 해당하는 자료에 대해서만 보호가 이루어지는 것으로 되어있어서, 이것만으로는 통계단위의 신뢰를 보호할 수 없다. 반면 해외의 입법들은 통계의 작성과정에서 수집한 개인에 관한 정보는 그것이 비밀에 해당하는지 여부를 불문하고 이를 비밀로 보호하고 있다.
또 통계법은 통계자료의 제3자 제공과 관련하여, 통계작성기관인 제3자가 통계작성기관에 통계작성을 위해 통계자료를 요청하여, 통계자료를 제공하는 경우는 ‘통계주체를 식별할 수 없도록 해야 한다’는 내용의 규정을 두고 있다. ‘특정의 개인이나 법인 또는 단체 등을 식별할 수 없는 형태로 통계자료를 처리한 후 제공하여야 한다’는 것이다. 그러나 ‘특정의 개인이나 법인 또는 단체 등을 식별할 수 없는 형태로 통계자료를 처리하는 것’은 식별 가능성을 제거하는 것이 아니므로 비밀보호로 충분하지 못하다.
통계의 비밀보호를 위해서는 통계법이 다음과 같이 개선될 필요가 있다. 통계의 비밀을 보호한다는 점을 명백하게 밝혀야 한다. 통계의 공표 시 통계단위가 식별되지 않도록 해야 한다는 점 또한 밝혀야 한다. 그 예외로는 유럽연합의 경우처럼 법령의 규정에 의한 경우로 한정하는 것이 좋을 것이다. 통계는 반드시 통계 목적으로만 활용되어야 함을 명백하게 밝혀야 한다. 통계자료에 관한 연구 목적의 활용에 대해서도 분명한 규율을 제정하는 것이 바람직하다.
나. 통계와 개인정보보호
개인정보보호법 제58조는 “공공기관이 처리하는 개인정보 중 통계법에 따라 수집되는 개인정보에 대해서 개인정보보호법 제3장 ~ 제6장을 배제한다.”는 규정을 두고 있다. 이와 관련하여 개인정보보호법의 적용이 배제되는 경우가 어떤 경우인지 해석에 논란의 여지가 있다.
물론 통계법에 따라 통계작성을 위한 개인정보 수집 시 개인정보보호법 제58조 제1항에 해당하여 개인정보보호법 제3장 ~ 제7장의 적용이 배제되더라도, 제58조 제4항에 의하여 목적에 따른 필요 최소한의 범위의 개인정보를 수집해야 하고, 목적 범위를 넘는 개인정보 수집을 해서는 안 되고, 목적 달성 후에는 즉시 파기해야 한다. 개인정보의 안전한 관리를 위하여 필요한 기술적·관리적 및 물리적 보호조치도 갖추어야 한다. 또한, 개인정보보호법 제3조 개인정보보호 원칙 및 제4조 정보주체의 권리보장도 준수되어야 한다.
해외의 법제는 통계작성을 위하여 개인정보를 처리하는 과정에서 개인정보보호를 개인정보보호법제와 통계 법제에서 함께 규율하는 경우가 대부분이고, 통계작성을 위한 개인정보의 수집이나, 통계자료에 포함된 개인정보의 보유, 이용, 제3자 제공 등과 관련해서도 필요한 규정에 대해서만 특칙을 두고 있는 경우가 대부분이다. 우리의 제도도 통계의 작성 및 활용에 있어 공공기관의 법령상 의무를 수행하는 과정에서 개인정보를 수집, 처리, 활용하는 경우와 마찬가지로 규율하도록 개선될 필요가 있다.
다. 통계 작성과정의 데이터 연계
통계의 작성과정은 통계 조사의 기획과 설계, 자료수집, 자료처리, 자료의 정리 및 공급의 절차로 구분할 수 있다.
우선 통계는 민감한 개인정보를 수집하여 작성하게 된다. 승인 통계의 경우는 통계법에서 개인정보의 수집을 강제하는 규정을 두고 있고, 이용, 제3자 제공을 허용하는 포괄적인 규정을 두고 있는 반면, 그에 대한 보호조치들은 규정이 매우 미비하다. 따라서 통계로 승인하는 절차는 매우 엄격하거나, 영향평가의 대상이 되거나, 법령의 체계를 갖춘 것이어야 바람직할 것이다.
현재 통계청은 통계작성 승인제도를 통계의 신뢰성 확보, 중복 방지의 관점에만 주안점을 두고 운영하고 있다. 통계작성을 승인할 때, 개인정보보호 원칙을 준수하고 있는지가 검토의 기준 중 하나가 되어야 한다. 현재 통계승인이나 지정통계의 지정을 결정하는 통계조정심의위원회는 통계청 내부의 조직으로 독립성과 개인정보보호에 관한 전문성을 갖추고 있다고 보기 어렵다. 성 평등을 위한 성별통계와 관련하여 여성가족부장관에게 의견조회를 의무화한 것처럼 개인정보보호위원회의 의견조회를 의무화하거나, 의견제시를 할 수 있는 제도적인 방안을 마련하는 것이 좋다.
현재 통계법에서는 데이터 연계에 대해서 특별한 규정은 두고 있지 않고, 연계의 요건에 대해서는 특별한 규정은 없다. 다만, 등록센서스 자료 수집 시 행정자료의 정보보호를 위한 운영규정·개인정보보호지침 등을 제정 운영하면서 행정자료 접근을 엄격히 제한하고, 주민등록번호·외국인등록번호 등 개인식별번호는 복원 불가능한 가상번호로 대체 후 즉시 삭제하며, 인터넷과 분리된 업무전용망에서 행정자료 통합관리 시스템을 통해 관리하고 있다고 한다.
임금근로일자리 행정통계의 사례에서처럼 행정통계를 작성하는 과정에서 여러 행정자료를 연계하여 활용하는 경우가 많다. 패널 조사 등 조사통계의 작성과정에서도 조사자료와 행정자료의 연계가 이루어진다. 예를 들어 의료패널도 국민건강보험공단의 건강보험자료와 연계를 한다. 이 외에도 통계청은 조사자료와 행정자료의 연계를 적극 추진하고 있다. 연계 대상인 행정자료로는 국세청 근로소득·사업소득·금융소득 자료 및 보건복지부 기초연금·생계급여·주거급여·장애인연금 자료 등 약 20여 종을 들었다. 인구총조사, 경제총조사 등 전수조사통계에도 데이터 연계는 광범위하게 활용된다. 인구총조사는 행자부 등 13개 정부기관 24종 행정자료를 융합한 등록센서스로 전환하여, 행정자료를 활용한 후 20% 표본조사를 하는 방식으로 변경되었다. 경제총조사도 국세청 사업자등록자료, 과세자료 등 8개 기관 20종 행정자료를 활용하여, 행정자료를 연계하고 있다.
통계의 원천이 되는 자료를 통계자료 혹은 마이크로데이터라고 부른다.
통계자료의 보유 및 관리에 대한 규율과 관련하여서, 현재 통계법은 ‘통계작성기관의 장은 통계의 보급 및 이용의 활성화를 위하여 통계자료를 보유·관리하여야 한다.’는 규정만을 두고 있고(통계법 제29조의 2), 시행령은 ‘전산 데이터베이스 등의 매체에 유실되지 않도록 보유·관리하여야 한다.’는 규정만을 두고 있다(시행령 제45조의 2 제1항).
통계자료의 비밀보호를 위해서 통계자료의 보유와 관리에 대한 규율을 마련할 필요가 있다. 특히 현재 개인정보보호법이 통계와 관련한 정보에 대한 개인정보보호법의 적용을 배제하고 있기 때문에 더더욱 통계법에 그에 관한 규정을 두어야 한다. 통계자료의 목적 달성 후 폐기 의무, 통계자료를 보유하는 동안에도 통계자료의 개인식별자를 대체번호 등으로 치환하고, 연계정보는 별도로 보관하면서 대체식별자로 처리된 통계자료를 활용하는 등의 안전조치가 바람직하다. 통계자료를 보유하는 동안 물적, 조직적, 관리적 안전조치를 유지하도록 하고, 특히 통계의 기밀유지를 위한 여러 규정을 마련할 필요가 있다.
라. 통계자료의 활용
통계법상 통계자료의 활용에 관한 규정은 통계작성의 목적을 위해서 활용하는 경우와 기타의 경우로 나누어 볼 수 있다. 통계의 작성을 위해서 필요한 경우는 통계법 제30조에서 규율하고 있다.
통계법은 통계작성 목적 외의 통계자료 활용에 대해서 제31조에 규정하면서, 특정의 개인이나 법인 또는 단체 등을 식별할 수 없는 형태로 통계자료를 처리한 후에는 제공하도록 규정하였다. 통계법은 통계자료의 이용신청을 할 수 있는 자를 제한하지 않고 있는데, 다만 해당 통계자료를 다른 자료와 대응 또는 연계함으로써 특정의 개인이나 법인 또는 단체 등의 식별이 가능하게 되는 경우, 사업체의 영업상 비밀을 침해하게 되는 경우에는 통계작성기관의 장이 통계자료를 제공하지 않을 수 있을 뿐이다.
따라서 통계자료가 특정 개인을 식별할 수 있는 형태로 제3자에게 제공되는 것은 엄격하게 금지해야 하고, 다만 예외적으로 이를 인정하려면 공공 연구의 목적으로 통계자료를 활용하는 경우로 제한하는 것이 바람직하다. 이 경우에도 해당 공공 연구는 국가기관이나 그에 준하는 신뢰성을 갖는 연구기관의 연구이어야 하고, 연구계획서에 대한 기관윤리위원회 등의 심의를 거치도록 하는 것이 바람직하다. 그리고 해당 통계자료를 제공받을 수 있는 시설을 제한하고, 통계자료의 유출이나 남용을 방지하기 위한 안전조치를 마련하는 것이 필요하다.
통계청 훈령인 국가통계자료제공 규정에 따르면 각 통계작성기관에 통계자료의 제공과 관련된 사항을 심의하기 위하여 통계자료제공심의회를 두도록 했다. 그런데 심의회는 통계자료의 제공에 대한 심의를 하는데, 심의회의 구성과 운영의 독립성은 거의 보장되지 않고 있다. 통계자료의 제공에 대한 심의는 독립성과 전문성이 보장될 수 있도록 구성하고, 운영하는 것이 바람직할 것이다. 통계자료의 비밀보호와 관련해서는 ‘실질적으로 식별되지 않도록’이라는 기준은 매우 불충분하므로, 자료제공 요청의 목적이나 제공 요청대상 정보의 내용에 따라서 세분화할 필요가 있다.
통계청은 통계청에서 작성하는 마이크로데이터 뿐만 아니라 정부 각 부처, 지자체, 연구기관 등 타 통계작성기관의 마이크로데이터를 한 곳에 모아 마이크로데이터 통합서비스라는 이름(MDIS)으로 제공하고 있다. 마이크로데이터의 경우 제공되는 형태에 따라서는 데이터연계나 데이터 결합이 가능한 경우도 있다.
마. 통계청의 데이터 연계·융합 활성화 추진전략
통계청은 데이터 연계, 융합을 활성화하려는 방안을 추진하고 있는 상황이다. 특히 통계청은 인구/가구, 사업체, 주택/건물, 경제활동 등 4개 분야의 통계작성 명부를 구축하고 있으며 등록부 간 연계로 범용 종합등록부의 구축을 추진할 계획이다.
통계청은 최근 공공데이터와 민간데이터 간 연계로 새로운 통계 정보 작성을 추진하고 있다. 그 시범적 사업으로 통계청 공공데이터와 민간기관 신용정보회사(코리아크레딧뷰로)의 빅데이터를 연계·분석하여 통계를 작성하였다.
통계청과 KCB의 데이터 연계는 신혼부부 데이터와 신용정보를 연계한 것인데, 통계청은 이를 저출산 대책 등 지원이 필요한 신혼부부에 관한 통계를 구축·분석한 것이라고 설명한다. 통계생산의 목적은 타당하다고 보이지만, 이 통계를 생산하는 과정에서 개인정보 침해를 최소화하려는 조치 등이 마련되어 있어야 하고, 절차가 통제되어야 한다.
통계청의 데이터로는 인구주택총조사의 등록센서스 정보(개인과 가구와 관련된 다양한 정보), 인구동향정보의 혼인 관련 정보, 국적 정보, 경제활동 정보로 임금근로, 일자리통계, 4대보험 정보, 근로소득 정보, 그 밖에 통계청의 각종 조사정보도 연계되었다. 이처럼 통계청이 신혼부부를 추출하여 표본을 구성하고, 이 데이터와 민간기업인 KCB의 데이터(소득, 신용등급, 대출잔액, 연체금액, 부채상환액, 신용카드 사용액 등)가 연계되었다. 물론 해당 신혼부부에게는 동의를 얻지 않은 것이다. 통계청은 KCB가 데이터 연계를 하고 연계키를 삭제하였으므로 법적으로 문제가 없다고 주장하나, KCB에게 데이터를 제공한 것이 현행법률상으로도 근거가 없는 것으로 보인다.
이와 같은 정보들을 연계하는 것이 타당한지에 대한 평가가 이루어졌는지도 알 수 없다. 통계청에서 통계작성을 위해서 데이터 연계를 할 때 관련 심사와 승인을 할 수 있는 독립적이고, 전문적인 기관이 필요하다.
통계청이 사전에 그 내용을 공개하지도 않고, 민간기업과의 협력을 통해서 서로 통계주체의 민감한 개인정보를 주고받은 것은 적절한 것으로 평가되기 어렵다. 특히 통계의 비밀보호는 엄격히 법률로서 보호되어야 하는바 법령의 규정도 없이 협력사업의 명목으로 이루어질 사안으로 보기는 어렵다.
통계자료의 공유나 활용은 엄격하게 통계의 비밀보호와 개인정보보호의 관점에서 규율되어야 한다. 그 목적은 공익목적의 연구로 제한되어야 하고, 그 절차도 비밀보호와 개인정보보호에 충분하도록 준수되어야 한다.
4) 개인정보 비식별 조치 전문기관을 통한 민간데이터 연계·결합 지원
2016년 7월 관계부처 합동으로 「범정부 개인정보 비식별 조치 가이드라인」(‘비식별 가이드라인’)을 발간하였다. 비식별 가이드라인은 빅데이터 분석에 활용하기 위해 서로 다른 정보집합물(데이터셋)을 결합하는 공공기관 및 민간기업의 업무를 지원하기 위하여 개인정보 비식별 조치 ‘전문기관’을 설립하도록 하였다.
가이드라인은 서로 다른 기업이 보유한 DB를 결합하는 과정에서 권장 방식대로 적정하게 비식별 조치가 이루어진 경우에는 개인정보가 아닌 것으로 추정되고, 이를 전문기관이 결합하는 것도 현행 개인정보보호법 상 목적 외 이용·제공 조항에 위반되지 않는다고 보았다.
2016년 8월 각 부처는 국가정보자원관리원(공공기관), 한국인터넷진흥원(공공기관, 통신), 한국정보화진흥원(통신), 금융보안원(금융), 한국신용정보원(금융), 사회보장정보원(보건·복지), 한국교육학술정보원(교육) 등을 분야별 개인정보 비식별 조치 전문기관으로 지정하였으며, 9월 한국인터넷진흥원에 ‘개인정보 비식별 조치 지원센터’가 설치되었다.
분야별 전문기관을 통해 데이터 연계·결합이 이루어지는 절차와 운영의 주요 내용은 다음과 같다. 첫째, 정보 집합물 결합을 원하는 A 회사와 B 회사가 같은 알고리즘을 적용하여 식별자를 임시 대체키로 전환하고, 결합 상대 정보 집합물도 비식별 조치 및 적정성 평가를 수행한다. 둘째, 비식별 조치된 정보를 전문기관에 제공하고 결합을 요청한다. 셋째, 임시 대체키를 활용하여 전문기관에서 결합을 수행한다. 넷째, 전문기관이 결합을 수행한 후 임시 대체키를 삭제한다. 다섯째, 전문기관이 결합한 결합 DB를 필요한 기업에게 제공한다.
지원기관 제도가 시작된 2016년 8월부터 2017년 9월까지 26차례에 걸쳐 총 347,522,005건의 민간기업의 데이터가 결합된 것으로 나타났다.
국내 전문기관을 통한 데이터 연계·결합 지원제도의 현황과 문제점은 다음과 같이 요약할 수 있다.
첫째, 결합 목적에 있어서 제한을 두고 있지 않다. 해외 데이터 연계 제도의 경우 공익, 연구, 통계 목적을 명확하게 한정하고 그에 대한 심사도 엄격한 데 비하여, 국내 전문기관이 수행한 대부분 사례에서 데이터 결합의 목적은 대출 심사나 마케팅 등 민간기업의 영리적 목적에 할애되어 있다.
둘째, 데이터 결합 단계별로 기능 분리가 이루어지고 있지 못하다. 개인정보보호위원회는 개인의 프라이버시 보호를 위해서는 데이터 연계과정에서 누구도 관련 데이터에 포함된 정보주체를 알아볼 수 없도록 하여야 하고, 이를 위해서 데이터 연계절차에 관여하는 각 기관의 기능이 분리되어야 하며 연계되는 데이터의 일부를 보유하고 있는 데이터 제공기관은 해당 과정에 참여할 수 없도록 해야 한다고 지적한 바 있다. 반면 국내 전문기관 제도의 경우 임시 대체키를 데이터 보유기관이 스스로 생성하여 그 메커니즘을 알도록 하였으며, 데이터 일부를 보유하고 있는 보유기관에 대규모로 결합된 데이터를 반출하고 해당 데이터의 재식별 검사도 데이터 보유기관이 스스로 수행하는 데 맡기고 있었다.
셋째, 투명성이 부족하다. 해외의 경우 데이터 연계가 승인된 모든 개인과 연구 프로젝트에 대한 등록사항이 공개되는 것이 원칙이다. 반면 국내 전문기관 제도의 경우 별도의 승인 요건이나 절차를 두고 있지 않음에도 데이터 결합 목적이나 결합 기업에 대한 정보가 공개되어 있지 않다.
넷째, 개인정보 보호법을 준수하고 있지 않다. 비식별화 가이드라인의 경우 개인정보 보호법의 보호 대상이 되는 ‘다른 정보와 쉽게 결합하여’ 알아볼 수 있는 개인정보를 매우 좁게 해석하고 비식별 조치를 취한 데이터셋에 대하여 개인정보가 아닌 것으로 추정하였다. 그러나 법원은 결합의 용이성과 관련하여 “구하기 쉬운지 어려운지와는 상관없이 해당 정보와 다른 정보가 특별한 어려움 없이 쉽게 결합하여 특정 개인을 알아볼 수 있게 되는 것”이라 판시한 바 있다. 전문기관을 통해 자사 보유 데이터셋을 다른 기업의 데이터셋과 결합시켜 돌려받은 기업으로서는 비식별 조치 이전 상태의 데이터셋 원본 또한 가지고 있으며, 임시 대체키를 직접 생성한 상태이므로 해당 데이터셋에서 개인을 알아볼 가능성이 있다. 이런 상태에서 특정한 비식별 조치를 기술적으로 취했다는 이유만으로 해당 데이터셋 모두를 개인정보가 아닌 것으로 추정한 것은 개인정보 보호법제의 적용을 자의적으로 면제한 것이다.
다섯째, 앞서의 문제점들이 종합적으로 작용한다면 비식별 정보의 재식별 위험성도 매우 높아진다. 실제 결합사례에서 비식별 조치가 개인을 더이상 식별하기 불가능한 수준에 이르렀다고 보기 어려운 경우도 있었다. 특히 데이터셋 일부를 보유한 기관에 결합데이터를 활용하려는 동기와 이해관계가 크게 작용하고 있을 때 비식별 조치는 매우 소극적으로 이루어질 수밖에 없다. 해외 사례에서처럼 절차적으로 어떤 참여기관도 전체 데이터셋의 내용이나 식별 데이터를 다룰 수 없도록 기능을 분리하지 않은 상태에서, 보유기업 스스로의 의지만으로 재식별화에 대한 억지 효과가 달성될 것이라고 기대하는 것은 무리이다.
5) 기타 정부 부처별 민간 데이터 연계·결합
가. 미래창조과학부
(구)미래창조과학부는 2013년부터 매년 「빅데이터 시범사업」을 실시해 왔으며, 2014년부터 「플래그십 프로젝트」 또한 공모해 왔다. 이들 시범사업 가운데 데이터 연계·결합 사례로는 2015년 비씨카드 컨소시움의 「빅데이터 시범사업」과 2016년 SK텔레콤의 「플래그십 프로젝트」를 들 수 있다.
2015년 비씨카드 컨소시움의 빅데이터 시범사업은 소셜 빅데이터와 카드 결제정보를 연계하여 소비 트렌드를 추출하고 트렌드 프로파일링 작업을 통해 신용카드 분야에서 타켓 마케팅을 실시하는 데 목표가 있었다. 컨소시움은 이 사업이 소셜 데이터와 카드사 내부의 빅데이터를 업계 최초로 결합하여 성과를 증명하였다고 자평하였다.
시범사업 결합에 사용된 BC카드의 신용카드 거래 데이터로는, 3천 6백만 명 유효카드 회원의 연령·성별·주소·연추정소득·전화번호·외국인여부·자동차보유여부·취미 등의 카드 회원 데이터, 261만 개 가맹점의 가맹점명·사업자주소·가맹점주소·전화번호·대표자정보·연평균 매출금액 등의 가맹점 정보 데이터 및 은행, 증권, 카드 등 30개 고객사 네트워크 데이터 등이었다. 결합에 사용된 소셜미디어 데이터로는, 국내 4,000개 뉴스사이트, 포털사이트 카페·블로그·지식인·댓글, 트위터·페이스북 페이지, 모네타·뽐뿌재테크 등 금융 커뮤니티/게시판, 통계청·서울시 공공데이터 및 지역단체 사이트 등 시드 웹사이트에서 수집한 정보였다.
이 사례의 경우 비록 개인 단위로 결합이 이루어지지는 않았으나 이와 같은 방식의 데이터 결합 사례는 소셜 데이터 수집 및 이용의 문제가 쟁점이 될 수 있다. 비록 정보주체인 소셜 계정 이용자가 스스로 공개한 정보이기는 하지만, 빅데이터 처리로부터 정보주체의 거부권이 보장될 필요가 있다. 현행 우리나라 개인정보보호법제의 경우 이 사업과 같은 프로파일링 처리로부터 정보주체의 권리를 보호하는 규율이 미흡하다.
SK텔레콤은 2016년도 미래성장동력 플래그십 프로젝트 사업으로 ‘개인정보 비식별 자료 생성·유통의 현장적용을 위한 실증 적용과제’를 수행하면서 SK텔레콤 가입자 데이터셋과 SCI 평가정보 데이터셋을 결합하였다.
SK텔레콤은 중금리 대출 이용자의 신용도 향상 가능성을 검증하기 위한 목적으로 SK텔레콤 가입자 중 제3자 데이터 제공동의를 한 서울지역 가입자를 대상으로 SCI와 직접 데이터 결합을 진행하였다. 이때 SK텔레콤의 결합 대상은 45개 항목이었으며, 비식별 조치 후 SK텔레콤 결합 대상자 3,754,040건과 SCI 결합 대상자 15,555,049건을 연계한 결과 970,553건의 결합(동기화)이 성공하였다. 이 결합은 별도의 임시 대체키를 생성하지 않고 가입자 성, 연령대, 가입자 성별을 키값으로 하여 결합을 수행하였으며 전문기관 개입 없이 자체적으로 결합을 수행하였다.
이와 같은 방식의 데이터 결합사례의 문제점은 개인정보 보호법의 준수 여부가 불명확하다는 것이다. 별도의 대체키 없이 데이터셋에 포함된 가입자 성, 연령대, 가입자 성별을 키값으로 하여 각 데이터셋에 속한 개인 1명을 직접 연계한 경우, 이 유일한 키값을 통해서도 원본 데이터셋에 포함된 개인을 알아볼 수 있다.
나. 국토교통부
국토교통부는 교통 분야 민간 데이터에 대한 접근을 위하여 법 제도적 장치 마련을 추진해 왔다. 2015년 12월 개정된 「대중교통의 육성 및 이용촉진에 관한 법률」(대중교통법)의 경우 교통카드데이터 수집 및 제공 체계를 규정하고 지속적 활용을 위한 교통카드데이터 통합정보시스템의 구축방안을 마련하였다. 대중교통법에서는 이 시스템에서 수집 및 활용하는 교통카드데이터에 대하여 ‘이용자를 알아볼 수 없는 형태로 가공한 자료’로 규정하고 있으며, 개별 교통카드 정산사업자는 교통카드 번호를 암호화하여 16~64자리의 가상번호로 변환한 뒤 이를 통합정보시스템에 제공한다.
2016년 12월까지 이루어진 교통카드빅데이터 통합정보시스템 1단계 구축사업으로, 교통카드 정산사업자인 한국스마트카드 수도권 교통카드데이터 및 기반데이터가 연계되었다. 2017년 2단계 구축사업으로 그 외 교통카드 정산사업자의 교통카드데이터 및 기반데이터를 연계하고, 특정부문사업자인 한국철도공사, SR, 시외버스, 고속버스의 교통카드데이터 및 기반데이터와 발권데이터에 대한 연계를 추진하고 있다.
연계된 교통카드데이터는 한국교통연구원 등 교통관련기관, 국가기관 및 지방자치단체 등에 제공되고, 한국교통연구원은 이와 같은 과정을 통해 수집한 교통데이터를 업무협약(MOU)을 통해 삼성카드가 보유한 소비데이터와 연계하는 사업을 추진 중이다.
국가 차원에서 교통카드데이터를 수집하고 이를 집적하여 빅데이터 통합정보시스템을 구축하는 정책은 본래 대중교통 현황조사라는 공익목적으로 추진되어 왔다. 그러나 대중교통법은 교통카드번호를 암호화하는 방식으로 안전조치를 취한 후에는 아무런 제한 없이 영리적 기업을 비롯하여 “교통카드데이터를 이용하려는 자” 모두에게 제공할 것을 규정하고 있고 공공과 민간이 보유한 교통카드데이터의 광범위한 연계 또한 예상되고 있다. 공공정책을 위해 교통 빅데이터를 구축 및 이용하고자 한다면 그 목적에 부합하도록 보관 기간은 물론 수집 및 제공을 제한하는 등 데이터 생애주기별로 세심하게 설계할 필요가 있다.
(5) 정책 제안
1) 관련 법제의 정비
첫째, 데이터 연계·결합 관련 법제의 정합성 유지.
현재 개인정보보호법, 전자정부법, 공공데이터법에는 개인정보의 제공, 공개, 연계·결합 등에 관하여 동일한 영역을 법률마다 상호 모순되게 규정하고 있다. 전자정부법은 행정정보 시스템의 연계·통합 등을 주로 효율성의 측면에서 평가하고 추진하는 법률이고, 공공데이터법은 공공데이터 이용 활성화를 목적으로 하고 있으므로, 이로 인해서 개인정보보호 원칙이 훼손되거나 정보주체의 개인정보자기결정권이 침해될 수 없다는 점을 분명히 해야 한다. 이런 관점에서 세 법의 관계를 설정하고, 정합성이 있도록 개선해 나가야 한다.
둘째, 개인정보보호법 정비: 연구 및 통계목적 개인정보 처리.
연구 및 통계 목적의 개인정보 처리를 위해 보다 구체적인 원칙과 조건을 포함하는 방향으로 현행 개인정보보호법을 개정할 필요가 있다.
① 공익을 위한 유지보존의 목적, 학술적·역사적 연구의 목적 또는 통계 목적의 개인정보 처리 시 정보주체의 권리를 보호하기 위해 적절한 안전조치를 취해야 한다. 이를 조건으로 최초 개인정보 수집 시 이에 대한 동의를 별도로 받지 않았어도 이와 같은 목적의 개인정보 처리를 허용하는 규정을 마련할 필요도 있다. 단, 이는 동의를 얻는 것이 현실적으로 불가능하거나, 지나치게 비용이 많이 들거나 기술적으로 어려운 경우로 한정하는 것이 바람직할 것이다.
② 개인정보가 학술적·역사적 연구 목적, 또는 통계 목적으로 처리되는 경우, 열람권, 수정권, 처리제한권, 처리 거부권, 처리에 대한 안전조치는 일부 제한될 수 있다.
한편, 개인정보보호법 제58조에서 통계법 등에 따라 수집되는 개인정보에 대해 제3장부터 7장까지 일률적으로 적용 배제하도록 한 것은 수정될 필요가 있다. 일부 예외적인 규정 외에는 개인정보보호법의 개인정보보호원칙이 모두 적용되어야 한다. 또 연구 및 통계 목적으로 제공된 정보는 해당 목적으로만 사용되어야 한다.
셋째, 보건의료 관련 법률 및 통계법 등의 정비.
① 보건의료 관련 법률의 정비
국민의 건강정보가 방대하게 수집·활용·연계되고 있음에도 불구하고, 국민건강보험법, 암관리법, 건강검진기본법 등 현행 보건의료 관련 법률에서는 건강정보의 수집, 활용, 제공 등의 근거가 부재하거나 모호한 경우가 많았다. 또한, 수집된 건강정보를 (준)영구적으로 보유하고 있는 등 개인정보보호 원칙에서 벗어나는 경우도 많았다. 건강정보 데이터의 연계·결합이 활성화되기 위해서라도 건강정보의 수집부터 활용·제공 등 전반적인 데이터 거버넌스 체제가 정비될 필요가 있다. 무엇보다 현행 보건의료 관련 법률을 재검토하여 법적 근거를 명확하게 하고, 개인정보보호 원칙을 위반하는 건강정보의 수집 관행을 바로잡을 필요가 있다.
② 통계법의 정비
현재 통계법의 규정은 통계의 비밀보호가 충분하지 못한 상황이다. 통계자료의 목적 달성 후 폐기 의무, 통계자료를 보유하는 동안에도 통계자료의 개인식별자를 대체번호 등으로 치환하고, 연계정보는 별도로 보관하면서 대체식별자로 처리된 통계자료를 활용하는 등의 안전조치를 취하도록 해야 한다. 통계자료를 보유하는 동안 물적, 조직적, 관리적 안전조치를 유지하도록 하고, 특히 통계의 기밀유지를 위한 여러 규정을 마련할 필요가 있다. 비밀보호의 예외적인 경우로 학술적 연구와 통계 목적의 통계자료 활용에 대해서는 그 절차와 기준에 대한 엄격한 법적 근거를 갖추는 것이 필요하다.
③ 연구 및 통계 목적의 데이터 활용 및 연계에 대한 법적 규율 마련
연구 및 통계 목적의 데이터 활용 및 연계에 대해서 그 활용을 허용하면서도 분명한 규율을 마련하여 엄격한 요건 하에서 이루어질 수 있도록 할 필요가 있다. 공익적 필요가 큰 반면에 당사자의 동의를 받는 것이 극히 곤란한 부득이한 경우에는 당사자의 동의 없는 데이터 활용 및 연계를 허용할 수 있겠지만, 비밀보호와 개인정보보호를 위한 다양한 안전장치를 마련해야 한다. (i) 접근이 승인된 연구기관에 의해 이루어질 것 (ii) 적절한 연구 제안서가 제출될 것 (iii) 학술 목적으로 요청된 기밀 정보의 유형이 적시될 것 (iv) (통계작성기관 등이) 인가한 접근 시설에서 접근이 제공될 것 (v) (학술 목적으로 통계자료에 대한 접근을 허용하는 경우) 해당 정보를 제공한 해당 통계작성기관이 승인할 것
데이터 연계와 관련해서는 유엔의 <통계 및 관련 연구 목적을 위해 수행되는 데이터 통합의 기밀성 관련 원칙과 가이드라인>을 각국의 법제 및 가이드라인에 반영할 수 있을 것이다. 뉴질랜드에서 2006년에 <데이터 통합 매뉴얼>의 두 번째 버전을 만들 때, 이 원칙과 가이드라인을 반영한 것을 참고할 필요가 있다.
대다수 국가의 법률들을 참고하여 투명성에 관한 규정도 마련하는 것이 바람직하다. 개인정보 감독기구가 데이터 거버넌스와 관련한 원칙 및 정책 수립, 다른 거버넌스 기구에 대한 자문 등 국내 데이터 거버넌스 체제 수립에 적극적인 역할을 할 필요가 있다.
2) 데이터 거버넌스 체제의 구축
국내에서는 개인정보의 비식별화 등 데이터의 개인 식별성을 어떻게 최소화할 것인지에 대해서만 초점을 맞추는 경향이 있다. 그러나 비식별화는 전반적인 거버넌스의 하나의 요소일 뿐이다. 데이터의 이용과 보호에 관련된 법제, 데이터 접근·연계 정책, 연구기관 혹은 데이터 연계기관의 인증, 심사절차, 데이터 접근 절차 등에 이르는 전반적인 거버넌스 체제를 갖추도록 노력할 필요가 있다. 제1절에서 다루었던 법제 개선과 함께, 전반적인 데이터 거버넌스 체제를 국가적인 차원에서 고민할 필요가 있다.
① 데이터 거버넌스 프레임워크
OECD 데이터 거버넌스 프레임워크의 8가지 핵심요소 등을 참고하여 보건의료, 통계 등 주요 분야에서 데이터의 수집, 이용, 제공, 연계 등 전반에 걸쳐 개인정보의 활용과 보호의 균형을 맞출 수 있는 데이터 거버넌스 프레임워크를 도입할 필요가 있다.
② 데이터 거버넌스 기구
정보 거버넌스 기구, 프로젝트 승인 기구, 연구윤리위원회 등 데이터 거버넌스 기구가 기능별로 설치될 필요가 있다. 개인정보보호위원회는 데이터 거버넌스와 관련한 원칙 및 정책 수립, 다른 거버넌스 기구에 대한 자문 등 국내 데이터 거버넌스 체제 수립에 적극적인 역할을 할 필요가 있다.
③ 연구 데이터 허브
데이터 연계·결합을 통한 데이터의 활용도를 높이고자 한다면, 연구 데이터 허브의 설치를 고려할 수 있다. 다만 과도한 개인정보 집적을 피할 수 있는 모델을 신중히 검토할 필요가 있다.
④ 데이터 연계 모델
콘텐츠 데이터의 보유, 연계키 생성, 데이터의 연계, 데이터의 제공 등을 담당하는 사람 혹은 기관의 분리를 통해 개인정보 침해의 위험성을 최소화하는 데이터 연계 모델을 도입할 필요가 있다. 해외의 많은 사례에서 ‘신뢰할 수 있는 제3자(TTP)’ 모델은 연계키를 생성하는 기관을 데이터 연계 및 접근을 제공하는 기관과 분리하고 있다는 점을 참고할 수 있다.
⑤ 안전조치
데이터의 수집, 저장, 연계, 제공 등 전 과정에 걸쳐서 개인정보 보호 및 보안을 위한 조치들이 취해져야 한다. 비식별화 등 데이터에 대한 안전조치(safe data) 뿐 아니라 연구자(safe people), 연구 프로젝트(safe project), 환경(safe environment), 결과물(safe results) 등에 대한 안전조치가 취해져야 한다. 다만 비식별 조치 등 안전조치를 취했다는 이유로 개인정보 보호법이 규정한 관련 책임이 일률적으로 면제되는 것은 아닐 것이다.
⑥ 연구지원단
연구의 설계, 승인, 안전한 환경에서의 데이터 접근에 있어서 연구자들을 돕는 창구 역할을 하는 연구지원단의 설치를 고려할 수 있다.
⑦ 투명성과 대중 참여
대중의 신뢰를 얻기 위해서는 높은 수준의 투명성과 참여가 필수적이다. 즉, 원칙과 절차, 진행된 사업 내용에 대한 정보를 투명하게 공개해야 하며, 정책 결정 과정에 시민들과 다양한 이해당사자들이 참여할 수 있도록 해야 한다.