
개인정보보호, 소프트웨어 정책


검증 과정은 무엇이 잘못됐는지 직접 찾아내지 못하지만, 그 과정은 때때로 우리에게 모델의 안정성에 문제가 있다는 것을 보여줄 수 있다.
데이터는 머신 러닝의 근원입니다. 기계 학습 및 딥 러닝 모델이 아무리 강력하더라도, 나쁜 데이터로 우리가 원하는 것을 결코 할 수 없다. 랜덤 노이즈 (즉, 패턴을 보기 어려운 데이터 포인트), 특정 범주형 변수 의 낮은 빈도, 대상 범주의 낮은 빈도 (대상 변수가 범주 형인 경우) 및 잘못된 숫자 값 등은 데이터가 모형을 망칠 수 있는 방법의 일부에 불과하다. 검증 과정은 무엇이 잘못됐는지 직접 찾아내지 못하지만, 그 과정은 때때로 우리에게 모델의 안정성에 문제가 있다는 것을 보여줄 수 있다.
학습/ 검증 / 테스트 분할

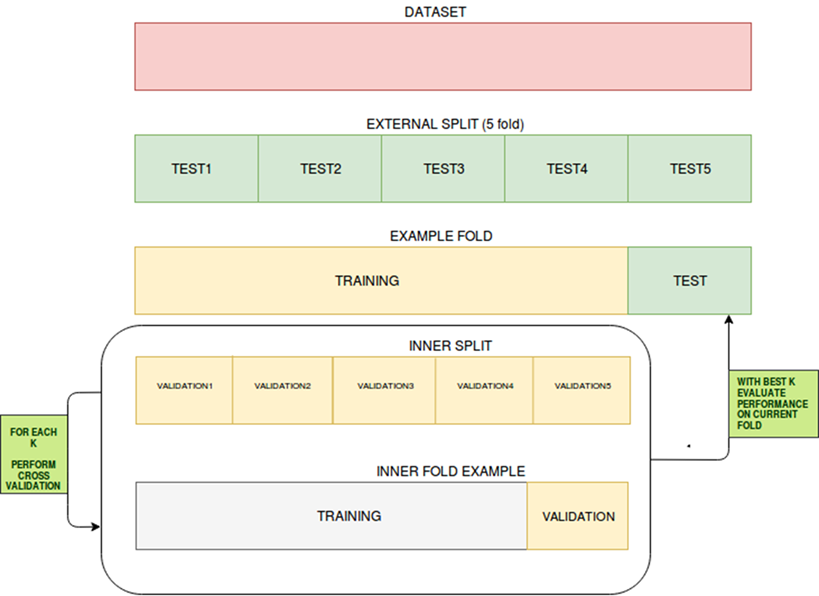
데이터를 검증하는 가장 기본적인 방법(즉, 모델을 테스트하기 전에 하이퍼파라미터 튜닝)은 누군가가 데이터에 대해 학습/검증/테스트 분할을 수행하는 것이다. 이에 대한 일반적인 비율은 80/10/10일 수 있으므로 충분한 훈련 데이터가 있는지 확인하십시오. 훈련 세트로 모델을 훈련한 후 사용자는 결과를 검증하고 사용자가 만족스러운 성능 지표에 도달할 때까지 유효성 검사 세트로 하이퍼 파라미터 튜닝을 진행한다. 이 단계가 완료되면 사용자는 성능을 예측하고 평가하기 위해 테스트 세트를 사용하여 모델을 테스트하는 단계로 이동한다.
교차 검증(Corss Validation)
교차 검증은 독립 데이터 세트에 대한 통계 예측 모델의 성능을 평가하는 기법이다. 모델과 데이터가 잘 연동되도록 하는 것을 목표로 한다. 교차 검증은 훈련 단계에서 수행되며, 사용자는 이 단계에서 모델이 데이터에 적합하지 않거나 과도하게 적합 하는지를 평가한다. 교차 검증에 사용할 데이터는 목표 변수에 대한 동일한 분포에서 생성되어야 하며 그렇지 않으면 모델이 실제에서 어떻게 수행될지에 대해 잘못 이끌 수 있다.
교차 검증에는 다음과 같은 다양한 유형이 있다.
-
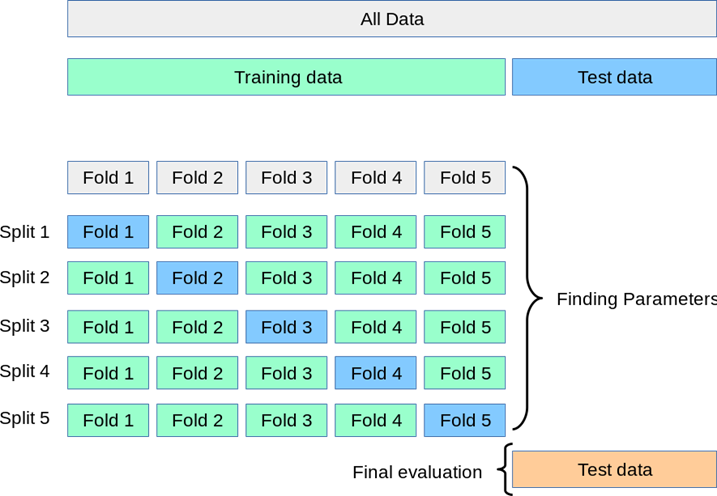
K-fold 교차 검증
- 우리는 훈련 단계에서 가능한 한 많은 데이터를 보존하고 검증 세트에 대한 귀중한 데이터를 잃을 위험이 없는 상황에서 K-fold 교차 검증이 도움이 될 수 있습니다. 이 기술은 훈련 데이터가 검증 세트를 위한 부분을 포기할 것을 요구하지 않을 것이다. 이 경우에, 데이터 세트는 k 개의 fold 로 나뉘어지고, 여기서 하나의 fold 는 테스트 세트로서 사용되고 나머지는 트레이닝 데이터 세트로서 사용될 것이며, 이는 사용자에 의해 지정된 바와 같이 n 회 반복 될 것이다. 회귀 분석에서 결과의 평균 (예: RMSE, R-Squared 등)이 최종 결과로 사용됩니다. 분류 설정에서 결과의 평균 (정확도, 진 양성 비율, F1 등)이 최종 결과로 간주됩니다.
- 훈련 단계를 위해 가능한 많은 데이터를 보존하고 검증 세트에 귀중한 데이터를 손실하지 않으려는 상황에서 K-fold 교차 검증이 도움이 될 수 있다. 이 기법은 훈련 데이터가 유효성 검사 세트의 일부분을 포기하도록 요구하지 않는다. 이 경우 데이터 세트는 k개의 fold 로 구분되며, 하나의 fold 는 테스트 세트로 사용되며 나머지는 훈련 데이터 세트로 사용되며, 이는 사용자에 의해 지정된 바와 같이 n 회 반복된다. 회귀 분석에서 결과의 평균(예: RMSE, R-Squared 등)을 최종 결과로 사용한다. 분류 설정에서는 결과의 평균(즉, Accuracy, True Positive Rate, F1, 등)을 최종 결과로 삼는다.
-
LOOCV (Leave-One-Out Validation)
- Leave-One-Out 유효성 검사는 k- fold 교차 검증과 유사하다. 반복은 지정된 시간 동안 수행되며 데이터 세트는 n-1 데이터 세트로 분할되며 제거된 데이터는 테스트 데이터가 된다. 성능은 k- fold 교차 검증과 동일한 방법으로 측정한다.

데이터 집합의 유효성을 확인하면 사용자에게 모델의 안정성에 대한 확신을 준다. 기계 학습이 사회의 측면을 관통하고 일상 생활에서 사용됨으로써, 그 모델들이 우리 사회를 대표하는 것이 더욱 절실해진다. 데이터 사이언티스트가 모델 제작 과정에서 직면할 수 있는 가장 흔한 함정은 오버핏(Overfitting)과 언더피팅(underfittin)이다. 검증은 재 학습이 필요하기 전에 일정 기간 동안 안정적이고 성능에 최적화되어 있는 모델의 관문이다.
원문 : https://www.kdnuggets.com/2020/01/data-validation-machine-learning.html