
개인정보보호, 소프트웨어 정책


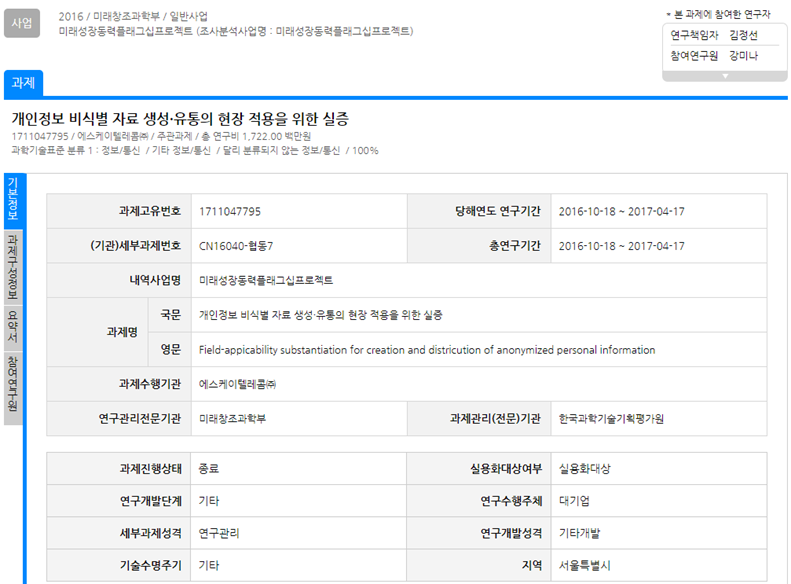
미래부의 산하기관인 한국과학기술정보연구가 2016-2017년도에 수행한 ‘개인정보 비식별 자료 생성유통의 현장 적용을 위한 실증 연구’ 에 의하면 ‘개인정보’를 비식별 조치를 하여도 재식별의 위험성이 있다는 결론을 내고 있다.
해당 과제는 국가과학기술지식정보서비스(NTIS)에 등록되어 있으나 연구에 대한 성과물인 연구 보고서는 사업이 완료되면 성과물로 등록하여야 하나 3년이 지난 현재에도 해당 보고서가 누락되어 있었다.
개인정보를 비식별 처리하여도 재 식별 위험성이 존재한다는 해외 연구는 있었으나, 국내 연구 사례로는 처음으로 정부가 연구 과제로 수행한 연구 결과에 대하여 미 공개한 사유가 “정부가 개인정보 활용 정책을 추진하는데 불리한 결과가 도출”된 내용으로 인하여 누락한 것이 아닌가 의구심이 든다.
만약 정부가 정책을 추진하는데 걸림돌이 된다는 판단으로 해당 보고서를 누락하였다면 이는 개인정보 활용이란 사회적 관심을 고려해 볼 때 단순한 보고서의 누락이 아니라, 국민의 알 권리를 심각하게 침해하는 행위로 해당 기관에 대한 감사 및 관련자에 대한 징계를 통하여 이와 같은 행위를 근절하여야 한다.
‘연구 보고서’ 결론 내용
외부기관 검증 수행
(1) TTA V&V(Verification & Validation) 인증 수행
◦ 원본 유사도 검증
- 추상화 기반 비식별화로 변환된 레코드 세트와 원본 레코드 세트 간의 유사도가 90% 이상 보존되는지 확인
- 시료데이터는 국민건강보험에서 제공하는 공개 데이터 중 “건강 검진 정보” 데이터 사용
◦ 원본 유사도 검증 결과
- 31가지 속성 값을 가진 100,000건의 데이터가 담겨있는 테이블에 대해 추상화 기반 비식별화를 수행했을 시, 원본 테이블과 변경된 테이블이 90%이상 유사한지 확인함
- 100,000건 데이터가 담긴 테이블 10개를 시료로 사용하여 시험하였고, 10개 테이블에 대하여 총 3회 시험 결과 원본테이블과 평균 98.64% 유사도가 유지되는 것을 확인함
비식별화 비교 분석
가. k-익명성 기법/MAS 비식별 알고리즘 실증 변환 결과 분석
(1) k-익명성 기법/MAS 비식별 결과 데이터 비교 분석 개요
(가) 실증데이터: 신용도
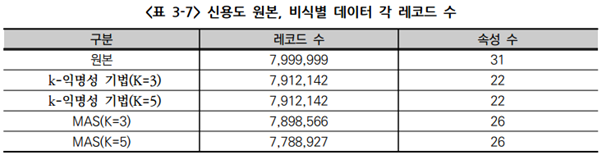
- 신용도 데이터 원본의 36개의 속성에 대하여 식별위험이 높은 속성 삭제(이동전화번호, 멤버쉽카드발급여부, 단말기제조사, 미납구분코드, 서비스개월수, 단말기종) 및 단순정보 속성(기준월) 삭제
- k-익명성 기법/MAS 비식별 조치 결과 데이터의 속성 수 차이는 k-익명성 기법의 경우 거주지역-시군구, 거주지역-읍면동 속성 삭제, MAS의 경우 가입일자를 가입년도, 가입월, 가입일 속성으로 분리
(나) 실증데이터: 장애우 거소지
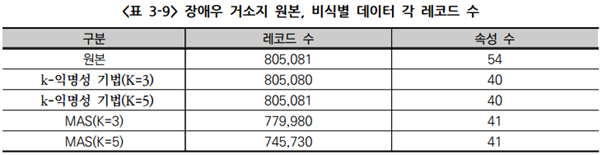
- 장애우 거소지 데이터 원본의 54개의 속성에 대하여 식별위험이 높은 속성 삭제(이동전화번호) 및 단순정보 속성 삭제(기준월, 기준시간)
- k-익명성 기법/MAS 비식별 조치 결과 데이터의 속성 수 차이는 MAS의 경우 원본 데이터 가입자생년월 속성을 연령과 연령대 두 속성으로 비식별 조치
(다) 실증데이터: 외국인 체류지
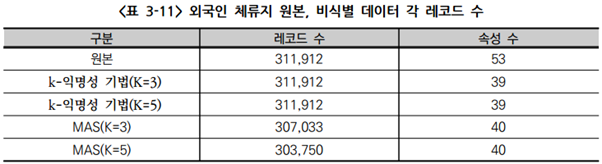
- 외국인 체류지 데이터 원본의 53개의 속성에 대하여 식별위험이 높은 속성 삭제(이동전화번호) 및 단순정보 속성 삭제(기준월, 기준시간)
- k-익명성 기법/MAS 비식별 조치 결과 데이터의 속성 수 차이는 MAS의 경우 원본 데이터 가입자생년월 속성을 연령과 연령대 두 속성으로 비식별 조치
k-익명성 기법/MAS 비식별 알고리즘 실증 변환 결과의 통계적 유사성 분석
(가) 통계적 유사성 분석의 필요성
- 원본 식별 데이터와 비식별 조치된 데이터 사이의 통계적 유사성을 정량적으로 평가함으로써 유통 전 데이터의 활용성 분석
(나) 분석 방법
① 원본유사도
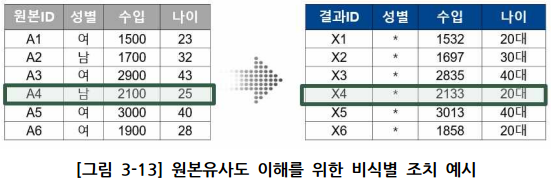
- 원본 데이터와 비식별 조치된 데이터 간 통계적 유사성을 0과 1 사이의 지표로 표현
- 해당 데이터 레코드 셋에 대하여 각 속성별 비식별화 값에 대응되는 원본 값과의 통계적 유사 정도를 속성 유사도로 정의
- 속성별 원본유사도는 해당 속성의 타입(수치형, 명목형)에 따라 계산 방법이 상이함
- 수치형 속성의 경우 원본 도메인 대비 변화율을 원본 유사도로 정의
- 명목형 속성의 경우 원본 도메인의 고유값 개수 대비 비식별 결과에 해당하는 값 개수의 비율에 따라 원본 유사도를 정의
- 해당 데이터 각 레코드에 존재하는 속성 유사도의 평균을 레코드 유사도로 정의
- 해당 데이터 레코드 셋의 모든 레코드 유사도의 평균을 테이블 유사도로 정의
② 잔존율
- 원본 데이터 셋의 레코드 수 대비 비식별 조치된 데이터 셋의 레코드 수를 백분율로 표기 및 분석
- 비식별 조치 과정에서 삭제되는 데이터의 비율을 지표로 분석함으로써 비식별 조치된 유통 데이터의 활용성 평가
(다) 신용도 실증데이터에 대한 분석 결과
① 각 기법별 원본 유사도
- 전체 속성 조합의 테이블 유사도 분석 결과 두 기법 모두 테이블 유사도가 90% 이상으로 데이터 유통 시 분석 활용 가능할 것으로 예상되나 상대적으로 k-익명성 기법의 비식별화 결과가 유사성이 낮음
- 이는 준식별자 속성 중 거주지역 속성 중 시군구/읍면동 속성을 지워내면서 해당 속성의 유사도가 크게 떨어지며 발생한 현상
② 각 기법별 잔존율
- 잔존율이 양 기법 모두 약 97% 이상으로 데이터 유통에 분석 활용 가능할 것으로 예상
- 일부 제거된 레코드는 재식별 가능 레코드로 유통이 완전 불가한 것으로 여겨짐
(라) 장애우 거소지 실증데이터에 대한 분석 결과
- 전체 속성 조합의 테이블 유사도 분석 결과 두 기법 모두 유사도가 97% 이상으로 데이터 유통 시 분석 활용 가능할 것으로 예상됨
- 잔존율이 양 기법 모두 약 97% 이상으로 데이터 유통에 분석 활용 가능할 것으로 예상
- 일부 제거된 레코드는 재식별 가능 레코드로 유통이 완전 불가한 것으로 여겨짐
(마) 외국인 체류지 실증데이터 대한 분석 결과
- 전체 속성 조합의 테이블 유사도 분석 결과 두 기법 모두 유사도가 97% 이상으로 데이터 유통 시 분석 활용 가능할 것으로 예상됨
- 잔존율이 양 기법 모두 약 97% 이상으로 데이터 유통에 분석 활용 가능할 것으로 예상
- 일부 제거된 레코드는 재식별 가능 레코드로 유통이 완전 불가한 것으로 여겨짐
k-익명성 기법/MAS 비식별 알고리즘 실증 변환 결과의 재식별 가능성 분석
(가) 재식별 가능성 분석의 필요성
- 비식별 조치된 레코드에 대하여 준식별자를 포함한 민감 속성들의 연결공격(linkage attack) 가능성을 정량적으로 평가하여 데이터 유통 전 안전성을 분석
- 원본 데이터 세트 중 유일한 속성 값을 갖는 레코드가 비식별 데이터 세트에서도 동일 속성값을 가지면서 유일하게 계속 남아있다면 연결 공격에 의한 재식별 위험에 노출될 수 있으므로 이에 대한 재식별 가능성 분석이 필요
(나) 분석 방법
① m-유일성 (m-uniqueness) 검사
- 원본 데이터와 동일한 속성 값의 조합이 비식별 결과 데이터에 최소 m개 존재해야 재식별 가능성 위험이 낮음
- m-유일성 검사 방법은 속성 조합 별로 n-차원 검사를 수행
- 비식별 조치된 결과 데이터에 대하여 준식별자/민감속성 구분 및 속성 타입 구분에 따라 6 종류 공격 타입을 분류하고 그에 따른 속성 조합을 선정
- 각 속성 조합 별로 원본 식별 데이터 속성 내에서 유일 속성조합 값이 변환된 결과 데이터 레코드에서도 동일하게 유일한 속성 조합 값의 개수를 집계
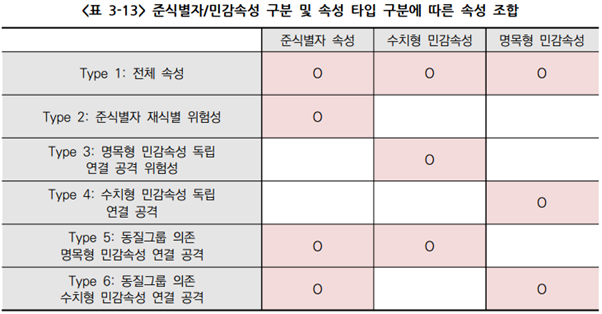
(다) 분석 결과
① 신용도 실증데이터에 대한 유일성 분석 결과
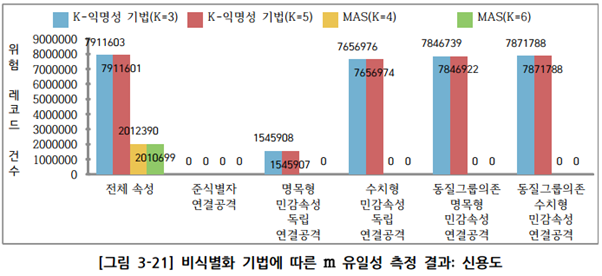
- k-익명성 기법 / MAS 기법은 모두 준식별자 속성 조합에 대한 재식별 위험성은 0으로 안전
- k-익명성 기법은 준식별자 속성 조합의 경우 재식별 가능성 위험이 없지만 빅데이터 활용을 위해 원본유지를 하는 다른 민감속성과의 조합으로 연결공격시 취약함
- KLT 프라이버시 모델을 적용 시, k-익명성의 취약한 부분을 보강하여 위험성을 현저하게 낮출 수 있음
- MAS 기법의 경우 대부분 속성 조합의 재식별 위험 레코드의 수가 0건으로 k-익명성 기법과 비교하여 현저하게 낮은 위험성을 보유함
② 장애우 거소지 실증데이터에 대한 유일성 분석 결과
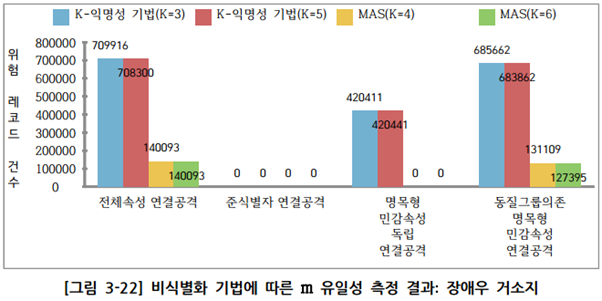
- k-익명성 기법 / MAS 기법은 모두 준식별자 속성 조합에 대한 재식별 위험성은 0으로 안전
- k-익명성 기법은 준식별자 속성 조합의 경우 재식별 가능성 위험이 없지만 빅데이터 활용을 위해 원본유지를 하는 다른 민감속성과의 조합으로 연결공격시 취약함
- KLT프라이버시 모델을 적용시, k-익명성의 취약한 부분을 보강하여 위험성을 현저하게 낮출 수 있음
- MAS 기법의 경우 대부분 속성 조합의 재식별 위험 레코드의 수가 0건으로 k-익명성 기법과 비교하여 현저하게 낮은 위험성을 보유함
③ 외국인 체류지 실증데이터에 대한 유일성 분석 결과
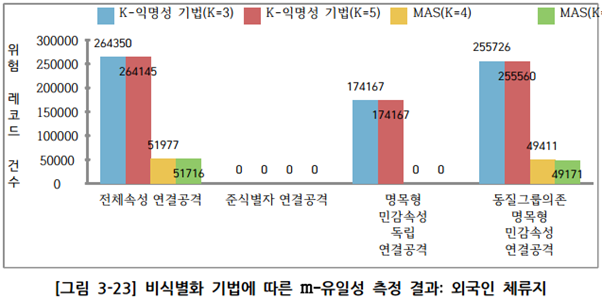
- k-익명성 기법 / MAS 기법은 모두 준식별자 속성 조합에 대한 재식별 위험성은 0으로 안전
- k-익명성 기법은 준식별자 속성 조합의 경우 재식별 가능성 위험이 없지만 빅데이터 활용을 위해 원본유지를 하는 다른 민감속성과의 조합으로 연결공격시 취약함
- KLT프라이버시 모델을 적용시, k-익명성의 취약한 부분을 보강하여 위험성을 현저하게 낮출 수 있음
- MAS 기법의 경우 대부분 속성 조합의 재식별 위험 레코드의 수가 0건으로 k-익명성 기법과 비교하여 현저하게 낮은 위험성을 보유함
개인정보 비식별 데이터의 연계 데이터 결과의 재식별 가능성 분석
-
연계 데이터 재식별 가능성 분석
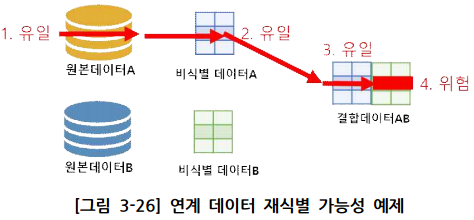
예) 원본 데이터 A에서 유일했던 레코드가 비식별 데이터 A에서도 유일하다. 그 레코드가 결합데이터 AB에서도 유일했을 때 연결 공격(linkage attack)에 의해 결합되었던 B의 민감속성이 식별될 위험이 생김
(나) 연계 데이터 재식별 가능성 분석에 대한 결과
① k-익명성 기법/MAS 결과 데이터 A에 대한 유일성 결과 검사 비교
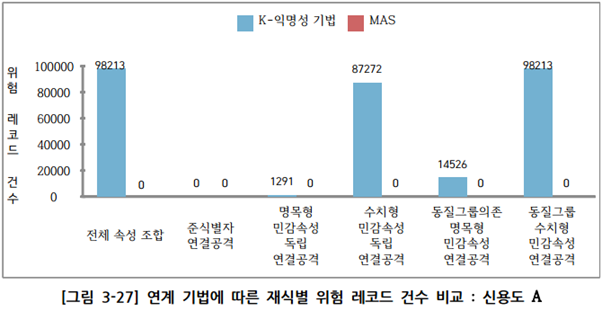
② k-익명성 기법/MAS 결과 데이터 B에 대한 유일성 결과 검사 비교

- k-익명성 기법은 준식별자 속성 조합의 경우 재식별 가능성 위험이 없지만 빅데이터 활용을 위해 원본유지를 하는 다른 민감속성과의 조합은 취약함
- KLT프라이버시 모델을 적용시, k-익명성의 취약한 부분을 보강하여 위험성을 현저하게 낮출 수 있음
- MAS 기법의 경우 연결형 유일성 검사에서 모든 속성 조합에 대해 위험 레코드가 0건 검출되어 연결공격에 대한 위험이 낮음
- 추가적으로 k-익명성 기법의 경우 비식별화 A-B 연계 결과에서 유일한 레코드가 비식별화 결과 A세트에서도 유일한 레코드 값을 가졌다면, 임시를 통해 원본을 찾아낼 수 있으며, 제공받은 연계 데이터 셋을 통해 대응되는 해당 레코드의 B사 측의 속성값이 유출되는 문제가 있음
- MAS 비식별화의 경우는 N:1 마이크로집계 방식으로 대응되는 원본을 식별하기 어려우며, 연계되어 제공된 B사의 속성값 또한 원본과 동일한 값이 아닌 비식별화 처리된 속성값이므로 레코드 재식별 가능성이나 속성값 유출의 위험성이 상대적으로 낮은 것으로 판단됨
현 제도의 제약점
(1) 현재 k-익명성 프라이버시 모델의 재식별 가능성 존재
(가) k-익명성, l-다양성 모델의 한계
- k-익명성은 같은 준식별자 값을 갖는 동질그룹의 수가 최소 k개 이상 되도록 가공하여 준식별자를 미리 알고 시도되는 준식별자 기반 재식별 공격을 방어하는 목적으로 2002년 개발됨
- 단점 : 동질그룹의 민감속성값이 모두 같을 경우 민감정보가 유츌될 수 있으므로 동질 그룹의 민감 속성값을 l-개 이상으로 가공하는 l-다양성 추가 적용 제안됨
- k-익명성, l-다양성 모델만으로는 민감속성(일반 속성자) 값을 미리 알고 시도되는 민감속성 기반 공격을 막지 못함
(예:공격자가 신림동에 사는 37세의 여자인 김화복씨가 페암에 걸린 사실을 미리 알고 있고 비식별 데이터에 30대, 여자, 신림동에 사는 5명의 동질 그룹에 페암 걸린 사람이 오직 한 사람일 경우 이 레코드가 김화복씨의 레코드임을 재식별함과 동시에 해당 레코드에 있는 김화복씨의 다른 민감속성 값을 알아낼 수 있음)
붙임자료 : 과기정통부